Dans cet article, nous examinerons le rôle clé du fichier robots.txt dans la gestion du trafic sur les sites web, discuterons de sa nécessité et fournirons des recommandations pour sa configuration afin d'optimiser l'indexation des pages. De plus, nous analyserons des exemples d'utilisation correcte des directives dans le fichier robots.txt et fournirons un guide pour vérifier l'exactitude de ses paramètres.
Pourquoi Robots.txt est nécessaire
Robots.txt est un fichier situé sur le serveur du site, à la racine de celui-ci. Il indique aux robots des moteurs de recherche comment analyser le contenu de la ressource. Une utilisation appropriée de ce fichier permet d'éviter l'indexation de pages indésirables, de protéger les données confidentielles et d'améliorer l'optimisation SEO et la visibilité du site dans les résultats de recherche. La configuration de robots.txt se fait via des directives, que nous examinerons plus loin.
Définition des directives dans Robots.txt
User-Agent
La directive principale est appelée « User-Agent », où nous définissons un mot-clé spécifique pour les robots. En détectant ce mot, le robot comprend que la règle lui est spécifiquement destinée.
Considérez un exemple d’utilisation de User-Agent dans le fichier robots.txt :
User-Agent: *
Disallow: /private/Cet exemple indique que tous les robots de recherche (représentés par le symbole «*") doit ignorer les pages situées dans le /privé/ répertoire.
Voici à quoi ressemble l'instruction pour des robots de recherche spécifiques :
User-Agent: Googlebot
Disallow: /admin/
User-Agent: Bingbot
Disallow: /private/Dans ce cas, le Googlebot le robot de recherche doit ignorer les pages dans le /administrateur/ répertoire, tandis que Bingbot devrait ignorer les pages dans le /privé/ répertoire.
Disallow
Disallow Indique aux robots de recherche les URL à ignorer ou à ne pas indexer sur le site web. Cette directive est utile pour masquer l'indexation de données sensibles ou de pages de contenu de mauvaise qualité. Si le fichier robots.txt contient cette entrée, Interdire : /répertoires/, les robots se verront refuser l'accès au contenu du répertoire spécifié. Par exemple,
User-agent: *
Disallow: /admin/Cette valeur indique que tous les robots devrait ignorer les URL commençant par /administrateur/Pour empêcher l'indexation de l'ensemble du site par des robots, définissez le répertoire racine comme règle :
User-agent: *
Disallow: /Autoriser
La valeur « Allow » agit à l'opposé de « Disallow » : elle autorise les robots de recherche à accéder à une page ou à un répertoire spécifique, même si d'autres directives dans le fichier robots.txt interdisent l'accès à celui-ci.
Prenons un exemple :
User-agent: *
Disallow: /admin/
Allow: /admin/login.htmlDans cet exemple, il est spécifié que les robots ne sont pas autorisés à accéder au /administrateur/ répertoire, à l'exception du /admin/login.html page, qui est disponible pour l'indexation et la numérisation.
Robots.txt et plan du site
Un plan de site est un fichier XML contenant la liste des URL de toutes les pages et de tous les fichiers du site indexables par les moteurs de recherche. Lorsqu'un robot accède au fichier robots.txt et voit un lien vers un plan de site XML, il peut l'utiliser pour trouver toutes les URL et ressources disponibles sur le site. La directive est spécifiée au format suivant :
Sitemap: https://yoursite.com/filesitemap.xmlCette règle est généralement placée à la fin du document, sans être liée à un agent utilisateur spécifique, et est traitée par tous les robots sans exception. Si le propriétaire du site n'utilise pas sitemap.xml, il n'est pas nécessaire d'ajouter cette règle.
Exemples de robots.txt configurés
Configuration de Robots.txt pour WordPress
Dans cette section, nous examinerons une configuration WordPress prête à l'emploi. Nous explorerons le blocage de l'accès aux données confidentielles et l'autorisation d'accès aux pages principales.
Comme solution toute faite, vous pouvez utiliser le code suivant :
User-agent: *
# Block access to files containing confidential data
Disallow: /cgi-bin
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /wp-content/plugins/
Disallow: /wp-content/themes/
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
# Allow access to the main site pages
Allow: /wp-content/uploads/
Allow: /sitemap.xml
Allow: /feed/
Allow: /trackback/
Allow: /comments/feed/
Allow: /category/*/*
Allow: /tag/*
# Prohibit the indexing of old versions of posts and parameterized queries to avoid content duplication or suboptimal indexing.
Disallow: /*?*
Disallow: /?s=*
Disallow: /?p=*
Disallow: /?page_id=*
Disallow: /?cat=*
Disallow: /?tag=*
# Include the sitemap (location needs to be replaced with your own)
Sitemap: http://yourdomain.com/sitemap.xmlBien que toutes les directives soient accompagnées de commentaires, approfondissons les conclusions.
- Les robots n'indexeront pas les fichiers et répertoires sensibles.
- Dans le même temps, les robots sont autorisés à accéder aux pages principales et aux ressources du site.
- l'interdiction d'indexer les anciennes versions des articles et des requêtes paramétrées est définie pour éviter la duplication de contenu.
- L'emplacement du plan du site est indiqué pour une meilleure indexation.
Nous avons donc considéré un exemple général d'une configuration prête à l'emploi, dans laquelle certains fichiers et chemins sensibles sont cachés de l'indexation, mais les répertoires principaux sont accessibles.
Contrairement à de nombreux CMS populaires ou sites personnalisés, WordPress propose plusieurs plugins facilitant la création et la gestion du fichier robots.txt. L'une des solutions les plus populaires à cet effet est : Yoast SEO.
Pour l'installer, vous devez :
- Accédez au panneau d’administration de WordPress.
- Dans la section « Plugins », sélectionnez « Ajouter un nouveau ».
- Recherchez le plugin « Yoast SEO » et installez-le.
- Activer le plugin.
Pour modifier le fichier robots.txt, vous devez :
- Accédez à la section « SEO » dans le menu latéral du panneau d'administration et sélectionnez « Général ».
- Allez dans l'onglet « Outils ».
- Cliquez sur « Fichiers ». Vous y trouverez différents fichiers, dont le fichier robots.txt.
- Saisissez les règles d'indexation nécessaires en fonction de vos besoins.
- Après avoir apporté des modifications au fichier, cliquez sur le bouton « Enregistrer les modifications dans robots.txt ».
Notez que chaque configuration de fichier robots.txt pour WordPress est unique et dépend des besoins et fonctionnalités spécifiques du site. Il n'existe pas de modèle universel convenant à toutes les ressources sans exception. Cependant, cet exemple et l'utilisation de plugins peuvent considérablement simplifier la tâche.
Configuration manuelle de Robots.txt
De même, vous pouvez configurer le fichier même en l'absence de CMS pour le site. L'utilisateur doit également télécharger le fichier robots.txt à la racine du site et spécifier les règles nécessaires. Voici un exemple, où toutes les directives disponibles sont indiquées :
User-agent: *
Disallow: /admin/ # Prohibit access to the administrative panel
Disallow: /secret.html # Prohibit access to a specific file
Disallow: /*.pdf$ # Prohibit indexing of certain file types
Disallow: /*?sort= # Prohibit indexing of certain URL parameters
Allow: /public/ # Allow access to public pages
Sitemap: http://yourdomain.com/sitemap.xml # Include the sitemapComment vérifier le fichier Robots.txt
En tant qu'outil auxiliaire lors de la vérification des erreurs dans le fichier robots.txt, il est recommandé d'utiliser les services en ligne.
Prenons l'exemple du Webmaster Yandex Service. Pour vérifier, vous devez insérer un lien vers votre site dans le champ correspondant si le fichier est déjà téléchargé sur le serveur. L'outil chargera ensuite la configuration du fichier. Vous pouvez également saisir la configuration manuellement :
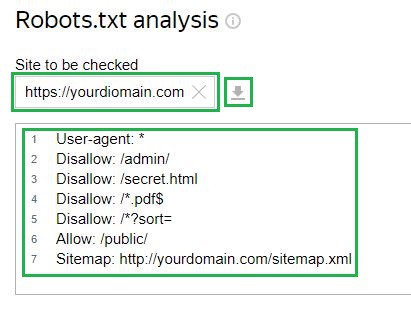
Ensuite, vous devez demander un contrôle et attendre les résultats :
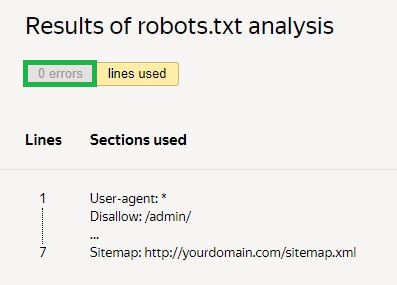
Dans l'exemple donné, il n'y a aucune erreur. Si c'est le cas, le service affichera les zones problématiques et les solutions pour les corriger.
Conclusion
En résumé, nous avons souligné l'importance du fichier robots.txt pour contrôler le trafic sur le site. Nous avons fourni des conseils sur sa configuration afin de gérer l'indexation des pages par les moteurs de recherche. Nous avons également examiné des exemples d'utilisation correcte de ce fichier et expliqué comment vérifier le bon fonctionnement de tous les paramètres.