Selles artiklis uurime faili robots.txt võtmerolli veebisaitide liikluse haldamisel, arutame selle olemasolu vajalikkust ja anname soovitusi selle seadistamiseks tõhusaks lehtede indekseerimise haldamiseks. Lisaks analüüsime näiteid õigete käskkirjade kasutamisest failis robots.txt ja anname juhendi selle seadete õigsuse kontrollimiseks.
Miks on faili Robots.txt vaja?
Robots.txt on fail, mis asub saidi serveris selle juurkataloogis. See annab otsingumootori robotitele teada, kuidas nad peaksid ressursi sisu skannima. Selle faili õige kasutamine aitab vältida soovimatute lehtede indekseerimist, kaitseb konfidentsiaalseid andmeid ning võib parandada SEO optimeerimise tõhusust ja saidi nähtavust otsingutulemustes. Faili robots.txt konfigureerimine toimub direktiivide kaudu, mida me vaatame edasi.
Direktiivide määramine failis Robots.txt
Kasutaja Agent
Esmane direktiiv on tuntud kui User-Agent, kus me määrame robotite jaoks spetsiaalse märksõna. Selle sõna tuvastamisel saab robot aru, et reegel on mõeldud just tema jaoks.
Vaatleme näidet User-Agenti kasutamisest failis robots.txt:
User-Agent: *
Disallow: /private/See näide näitab, et kõik otsingurobotid (esindatud sümboliga "*") peaks ignoreerima lehti, mis asuvad asukohas /privaatne/ kataloog.
Siin on juhis konkreetsete otsingurobotite jaoks.
User-Agent: Googlebot
Disallow: /admin/
User-Agent: Bingbot
Disallow: /private/Sel juhul on Googlebot otsingurobot peaks ignoreerima lehti /admin/ kataloog, samas Bingbot tuleks ignoreerida lehti /privaatne/ kataloog.
tagasi lükkama
tagasi lükkama ütleb otsingurobotidele, millised URL-id veebisaidil vahele jätta või indekseerimata jätta. See direktiiv on kasulik, kui soovite peita tundlikke andmeid või madala kvaliteediga sisulehti otsingumootorite indekseerimise eest. Kui fail robots.txt sisaldab kirjet Keela: /kataloogid/, siis keelatakse robotitel juurdepääs määratud kataloogi sisule. Näiteks
User-agent: *
Disallow: /admin/See väärtus näitab seda kõik robotid peaks ignoreerima URL-e, mis algavad tähega /admin/. Kogu saidi indekseerimise blokeerimiseks robotite poolt määrake juurkataloog reeglina:
User-agent: *
Disallow: /lubama
Väärtus "Luba" toimib vastupidine väärtusele "Disallow": see võimaldab otsingurobotidel juurdepääsu konkreetsele lehele või kataloogile, isegi kui muud failis robots.txt olevad direktiivid keelavad sellele juurdepääsu.
Kaaluge näidet:
User-agent: *
Disallow: /admin/
Allow: /admin/login.htmlSelles näites on täpsustatud, et robotitel ei ole lubatud juurdepääsu /admin/ kataloog, välja arvatud /admin/login.html leht, mis on saadaval indekseerimiseks ja skannimiseks.
Robots.txt ja saidiplaan
Saidiplaan on XML-fail, mis sisaldab kõigi saidi lehtede ja failide URL-ide loendit, mida otsingumootorid saavad indekseerida. Kui otsingurobot pääseb juurde failile robots.txt ja näeb linki saidiplaani XML-failile, saab ta seda faili kasutada saidil kõigi saadaolevate URL-ide ja ressursside leidmiseks. Direktiiv on täpsustatud kujul:
Sitemap: https://yoursite.com/filesitemap.xmlSee reegel paigutatakse tavaliselt dokumendi lõppu, ilma et see oleks seotud konkreetse kasutajaagendiga, ja seda töötlevad eranditult kõik robotid. Kui saidi omanik ei kasuta sitemap.xml, pole reeglit vaja lisada.
Näited failist Konfigureeritud Robots.txt
Fati Robots.txt seadistamine WordPressi jaoks
Selles jaotises käsitleme WordPressi valmiskonfiguratsiooni. Uurime konfidentsiaalsetele andmetele juurdepääsu blokeerimist ja põhilehtedele juurdepääsu võimaldamist.
Valmislahendusena saate kasutada järgmist koodi:
User-agent: *
# Block access to files containing confidential data
Disallow: /cgi-bin
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /wp-content/plugins/
Disallow: /wp-content/themes/
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
# Allow access to the main site pages
Allow: /wp-content/uploads/
Allow: /sitemap.xml
Allow: /feed/
Allow: /trackback/
Allow: /comments/feed/
Allow: /category/*/*
Allow: /tag/*
# Prohibit the indexing of old versions of posts and parameterized queries to avoid content duplication or suboptimal indexing.
Disallow: /*?*
Disallow: /?s=*
Disallow: /?p=*
Disallow: /?page_id=*
Disallow: /?cat=*
Disallow: /?tag=*
# Include the sitemap (location needs to be replaced with your own)
Sitemap: http://yourdomain.com/sitemap.xmlKuigi kõikidele käskkirjadele on lisatud kommentaarid, süvenegem järeldustesse.
- Robotid ei indekseeri tundlikke faile ja katalooge.
- Samal ajal võimaldatakse robotitele juurdepääs saidi põhilehtedele ja ressurssidele.
- Sisu dubleerimise vältimiseks on seatud postituste vanade versioonide ja parameetritega päringute indekseerimise keeld.
- Paremaks indekseerimiseks on näidatud saidiplaani asukoht.
Seega oleme vaatlenud üldist näidet valmis konfiguratsioonist, kus mõned tundlikud failid ja teed on indekseerimise eest peidetud, kuid peamised kataloogid on juurdepääsetavad.
Erinevalt paljudest populaarsetest CMS-idest või eritellimusel kirjutatud saitidest on WordPressil mitu pistikprogrammi, mis hõlbustavad faili robots.txt loomist ja haldamist. Üks populaarsemaid lahendusi selleks on Yoast SEO.
Selle installimiseks peate:
- Minge WordPressi administraatoripaneelile.
- Jaotises "Pluginad" valige "Lisa uus".
- Leidke pistikprogramm "Yoast SEO" ja installige see.
- Aktiveerige plugin.
Faili robots.txt muutmiseks peate tegema järgmist.
- Minge administraatori paneeli külgmenüüs jaotisesse "SEO" ja valige "Üldine".
- Minge vahekaardile "Tööriistad".
- Klõpsake nuppu "Failid". Siin näete erinevaid faile, sealhulgas robots.txt.
- Sisestage vajalikud indekseerimisreeglid vastavalt oma vajadustele.
- Pärast failis muudatuste tegemist klõpsake nuppu "Salvesta faili robots.txt muudatused".
Pange tähele, et iga WordPressi faili robots.txt seade on unikaalne ja sõltub saidi konkreetsetest vajadustest ja funktsioonidest. Pole olemas universaalset malli, mis sobiks eranditult kõikidele ressurssidele. See näide ja pistikprogrammide kasutamine võivad aga ülesannet oluliselt lihtsustada.
Faili Robots.txt käsitsi seadistamine
Samamoodi saate seadistada faili konfiguratsiooni isegi siis, kui saidi jaoks pole valmis CMS-i. Samuti peab kasutaja üles laadima faili robots.txt saidi juurkataloogi ja täpsustama vajalikud reeglid. Siin on üks näidetest, milles on näidatud kõik saadaolevad direktiivid:
User-agent: *
Disallow: /admin/ # Prohibit access to the administrative panel
Disallow: /secret.html # Prohibit access to a specific file
Disallow: /*.pdf$ # Prohibit indexing of certain file types
Disallow: /*?sort= # Prohibit indexing of certain URL parameters
Allow: /public/ # Allow access to public pages
Sitemap: http://yourdomain.com/sitemap.xml # Include the sitemapKuidas kontrollida faili Robots.txt
Abivahendina faili robots.txt vigade kontrollimisel on soovitatav kasutada võrguteenuseid.
Mõelge näitele Yandexi veebimeister teenust. Kontrollimiseks tuleb vastavale väljale sisestada link oma saidile, kui fail on juba serverisse üles laaditud. Pärast seda laadib tööriist ise faili konfiguratsiooni. Samuti on võimalus konfiguratsioon käsitsi sisestada:
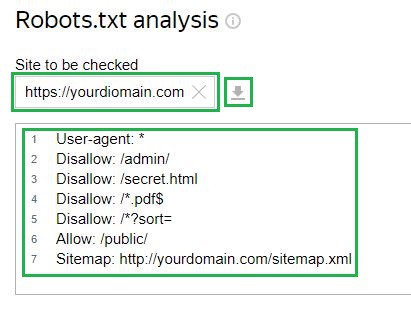
Järgmiseks peate taotlema kontrolli ja ootama tulemusi:
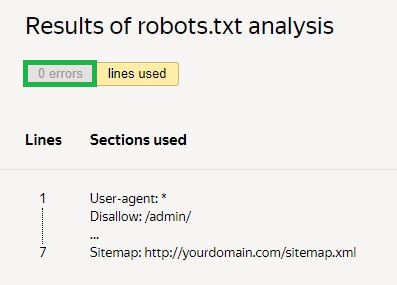
Antud näites vigu pole. Kui neid on, näitab teenus probleemseid kohti ja nende parandamise viise.
Järeldus
Kokkuvõttes rõhutasime, kui oluline on faili robots.txt saidi liikluse juhtimiseks. Andsime nõu selle kohta, kuidas seda õigesti seadistada, et hallata seda, kuidas otsingumootorid lehekülgi indekseerivad. Lisaks sellele vaatasime ka näiteid selle faili õige kasutamise kohta ja andsime juhiseid, kuidas kontrollida, kas kõik seaded töötavad õigesti.