當伺服器超載時(無論是虛擬的還是專用的),都會導致網站載入緩慢,並產生令人煩惱的錯誤而不是內容。有必要仔細監測其參數並及時進行資源分析,以避免這樣的結果,
接下來,我們將研究如何使用託管服務提供者的工具以及透過伺服器端的終端來診斷單一資源。此外,我們將考慮各種方法來解決與系統效能不佳相關的問題。這些說明適用於任何運行 Linux 作業系統的伺服器,無論預先安裝了什麼軟體。
透過 VMmanager 檢查伺服器資源
VMmanager 虛擬化工具是最簡單但同時通用的診斷解決方案。它在確保高效管理方面發揮關鍵作用 專用 or 虛擬服務器 在大多數現代託管服務提供者上。作為範例,檢查將在該工具的第 6 版上進行,但是,先前的版本也可能進行類似的診斷。
為了進行分析,您需要前往 虛擬機管理器 控制面板並選擇所需的虛擬機器:
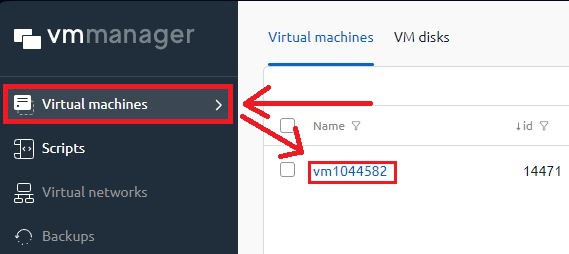
接下來,使用者可以立即即時看到資源的使用情況。如需更詳細的統計數據,需要選擇「參數」:
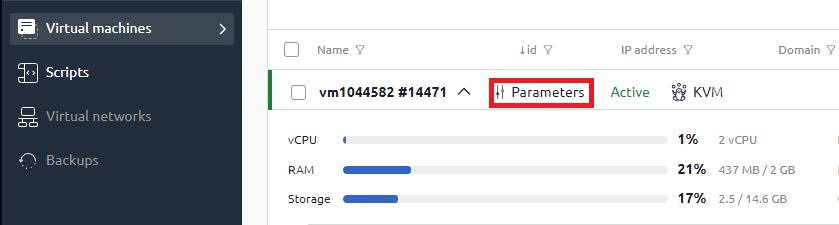
頂部的詳細統計資訊標籤顯示了一般伺服器特性和虛擬化類型。在圖表上,您可以即時看到網路擁塞、處理器負載、RAM 和磁碟空間使用情況:
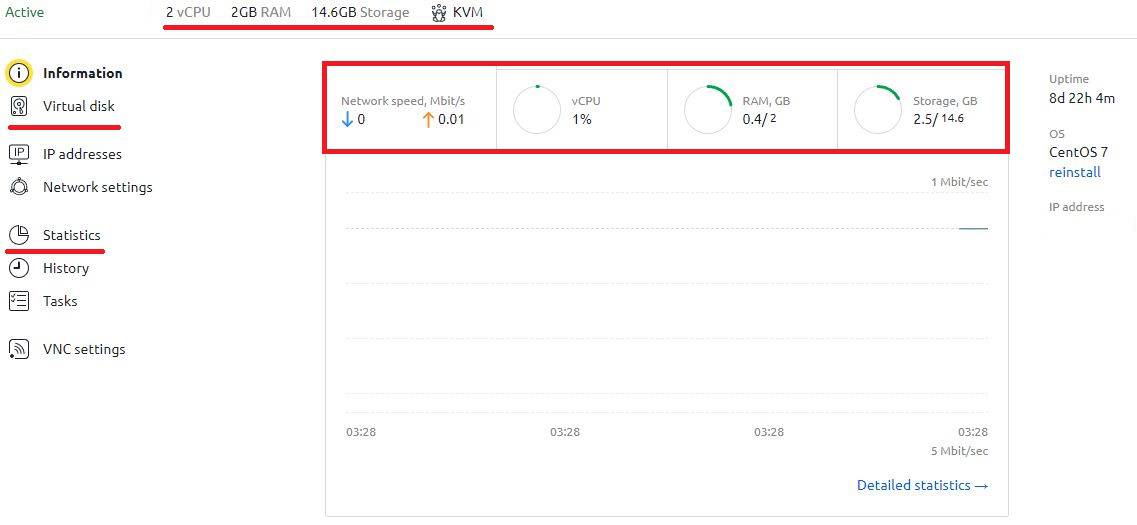
若要對一定時期內的磁碟空間或資源統計進行更詳細的分析,必須選擇適當的選單項目。有關虛擬磁碟的資訊顯示格式如下:
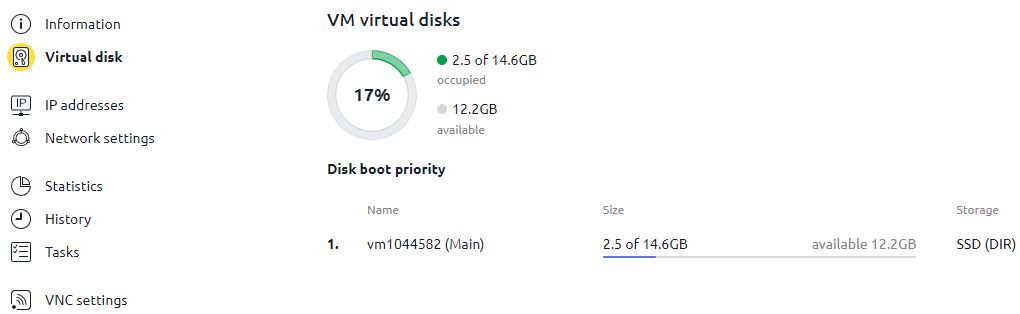
特定資源的負載統計資料以方便的圖表形式顯示:
可以顯示一天、一週、一個月、一年的負載圖,或手動選擇必要的日期。顯示所有主要資源:處理器、RAM、儲存、網路介面。
許多用戶希望在一定時期內均勻地利用資源。但情況並非總是如此。例如,即使在空閒模式下,網路介面可能看起來也類似:
在這種情況下不需要採取任何措施。但是,就處理器、RAM 或磁碟儲存而言,伺服器不應該持續使用 100% 的資源;建議負載不超過70%。
在終端機中檢查伺服器資源
總負荷分析
我們之前已經研究過 伺服器資源的常規診斷 文章。我們在那裡討論了標準工具,例如 頂部/頂部,也研究了安裝和配置 網絡數據 實用程序,它允許我們透過瀏覽器監控伺服器資源。在本文中,我們將討論 HTOP 作為替代 最佳 用於一般系統資源分析的實用程式。
該工具預設未預先安裝在 Linux 發行版中,因此讓我們從安裝開始。對於 Debian/Ubuntu,我們使用以下命令:
apt-get install htop對於 CentOS,使用 EPEL 儲存庫。它們預設是禁用的,因此第一個命令負責添加它們,第二個命令負責安裝 HTOP:
yum -y install epel-release
yum install htop -y安裝後,您可以從應用程式選單或終端機中使用相應的命令開啟該實用程式:
htop因此,用戶將能夠看到有關係統的所有資訊:
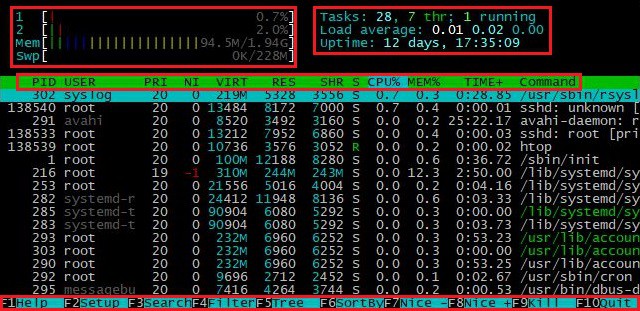
左上角顯示處理器數據,包括每個核心、RAM 和交換記憶體的使用情況。 Linux 中的交換記憶體用於在 RAM 不足的情況下確保系統穩定性。在右上角您可以看到處理器負載和活動任務的數量。中心部分展示具有排序能力的活動過程。下部提供有關熱鍵和功能的資訊。 「幫助」部分包含該程式功能的詳細描述:
在診斷系統本身之前,必須準確了解伺服器上使用了多少核心/處理器。用戶可以在左上角找到他們的價值 HTOP 效用:

或透過運行命令:
nproc根據獲得的值,將計算允許的總負載(右上角的平均負載)。在我們的例子中,它等於 2,這意味著最大負載是 2.0。但這並不意味著系統在負載 2.0 下會完全凍結。這個數字可能會更高,但在這種情況下,所有其他任務都將在佇列中,並且伺服器本身將被載入。理想值被認為是負載不超過70%。例如,單處理器伺服器上的平均負載應在 0.7 以內。就上述範例中的伺服器而言,良好的指標值不高於 1.4。
使用 HTOP 或其類似物,使用者需要評估主要資源:平均處理器負載、RAM 使用率、磁碟空間和網路介面。如果資源最少,則需要按 CPU 使用率對進程進行排序,找出消耗高的操作,然後最佳化或終止它們。如果無法關閉程式或最佳化失敗,建議考慮切換到配置更強大的伺服器。
檢查可用 RAM
在本節中,我們將仔細研究任何伺服器運行的一個重要方面——足夠的可用 RAM。
透過終端機檢查任何 Linux 系統上的可用 RAM 的最簡單方法是使用以下命令:
free -m在輸出中我們得到以下以兆位元組為單位的資料:總 RAM、已使用 RAM、可用 RAM 和快取 RAM,以及交換磁碟區:

該工具對於獲取特定時間點的一般數據很有用。對於動態 RAM 使用情況診斷,我們建議 vmstat的 實用程序,它允許我們配置輸出資訊的更新頻率:
vmstat 1在上面的例子中,資料將每秒更新一次。輸出格式類似 :
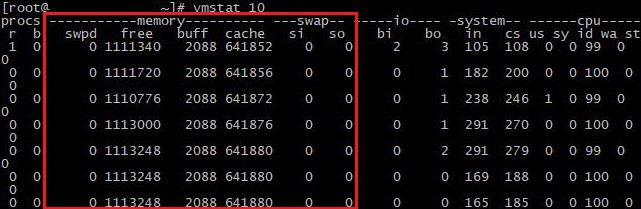
該工具還提供一般系統信息,但在我們的例子中,只有負責 RAM(即內存和交換)的列才是重要的。所有值均以千位元組為單位。讓我們更詳細地看一下:
記憶體應用 (內存):
- 韋斯特:虛擬記憶體換成實體記憶體。
- :可用的實體記憶體(RAM)。
- 淺黃色:磁碟寫入之前用作緩衝區的記憶體。
- 高速緩存:使用記憶體作為緩存,以加快存取速度。
交換
- si:使用記憶體作為緩存,以加快存取速度。
- so:從實體記憶體寫入交換記憶體的資料。
另外,值得一提的是,所有系統資源診斷實用程式最初都會從日誌中取得資料。對於RAM,使用者可以透過開啟對應的檔案直接查看資料:
cat /proc/meminfo輸出相當廣泛,但只需專注於第一筆記錄來分析記憶體:
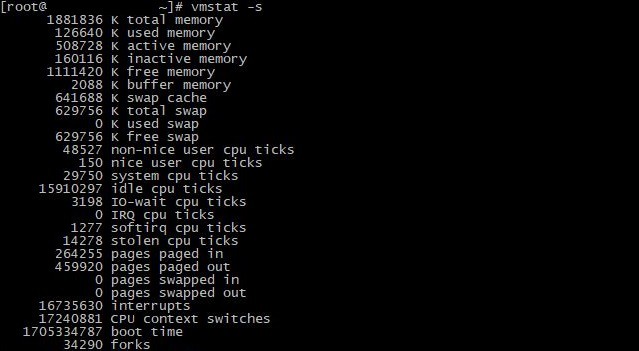
RAM 使用過多的問題通常與特定任務或進程有關。一開始,使用常用工具進行診斷以識別有問題的流程就足夠了。作為解決方案,您可以考慮優化特定的應用程序,如果我們談論大量信息,則啟用快取和資料壓縮,或增加伺服器配置。
磁碟空間控制
伺服器磁碟空間的診斷與其其他資源的診斷同樣重要。通常,需要檢查的訊號是:無法建立或寫入現有檔案、系統效能緩慢以及各種輸入/輸出錯誤。
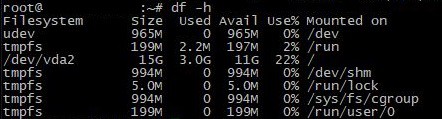
最方便的檢查方法是使用以下命令:
df -h作為回應,該工具將顯示所有已安裝磁碟分割區的資訊:
您可以使用此命令進行更詳細的目錄監控:
du -hs /*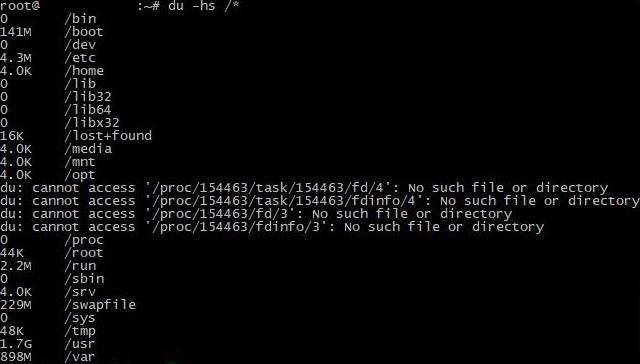
這樣,使用者就能知道每個目錄佔用了多少空間。要恢復系統效能,您需要優化消耗最多記憶體的磁碟分割區。建議不要讓使用的可用空間超過總量的80-90%;剩下的10-20%應該足以保證系統穩定運作。如果無法最佳化,建議增加磁碟空間。這可以透過新增磁碟或擴展現有磁碟以及使用雲端儲存來實現。無論選擇哪種解決方案,建議始終製作備份以避免檔案遺失。
網路介面檢查
伺服器診斷的最後一個但同樣重要的方面是檢查網路介面。這 網絡豬 如果您想要即時獲取有關網路進程所佔流量的一般信息,可以使用該實用程式。
在 Cent OS 上安裝並啟動:
yum install nethogs
nethogs對於 Debian/Ubuntu:
apt-get install nethogs
nethogs該工具將顯示目前正在使用網路資源的進程:

我們推薦使用 伊夫托普 進行更詳細的分析。
在 Cent OS 上安裝並啟動:
yum install iftop
iftop對於 Debian/Ubuntu:
apt-get install iftop
iftop程式輸出是活動連線列表,其中顯示 IP 位址、連接埠、傳輸的資料量和傳輸速度。主要的程式優勢是網路通道載入的視覺化設計:
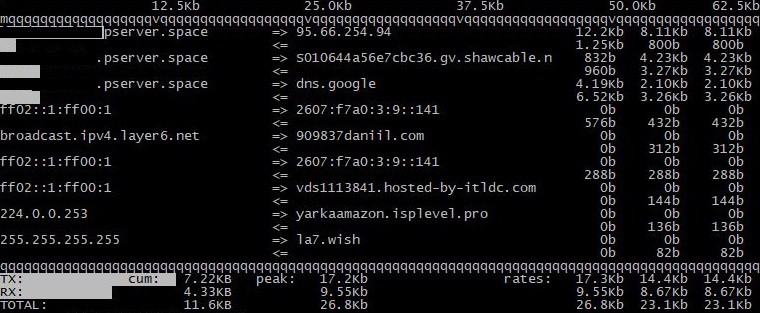
在診斷伺服器網路通道並確定高負載問題後,建議增加託管提供者端的網路連線頻寬或最佳化特定問題介面的設定。作為備份工具,您可以使用各種監控系統快速追蹤網路活動的變化,並在必要時根據要求定期更新網路基礎架構。
結語
總之,需要強調的是,診斷伺服器資源是有效管理 虛擬 以及 專用 伺服器.本文為我們提供了查看完整伺服器分析的主要工具的可能性,並為解決可能出現的問題提供了實用的建議。定期的系統診斷可以讓伺服器無縫運行,即使沒有使用者主動參與。