اس مضمون میں، ہم ویب سائٹس پر ٹریفک کے نظم و نسق میں robots.txt فائل کے کلیدی کردار کا جائزہ لیں گے، اس کی موجودگی کی ضرورت پر تبادلہ خیال کریں گے، اور صفحہ اشاریہ سازی کے مؤثر انتظام کے لیے اسے ترتیب دینے کے لیے سفارشات فراہم کریں گے۔ مزید برآں، ہم robots.txt فائل میں درست ہدایات کے استعمال کی مثالوں کا تجزیہ کریں گے اور اس کی ترتیبات کی درستگی کو چیک کرنے کے بارے میں ایک گائیڈ فراہم کریں گے۔
Robots.txt کی ضرورت کیوں ہے۔
Robots.txt ایک فائل ہے جو سائٹ کے سرور پر اس کی روٹ ڈائرکٹری میں واقع ہے۔ یہ سرچ انجن روبوٹ کو مطلع کرتا ہے کہ انہیں وسائل کے مواد کو کیسے اسکین کرنا چاہیے۔ اس فائل کا صحیح استعمال ناپسندیدہ صفحات کی انڈیکسنگ کو روکنے میں مدد کرتا ہے، خفیہ ڈیٹا کی حفاظت کرتا ہے، اور SEO کی اصلاح اور تلاش کے نتائج میں سائٹ کی مرئیت کی کارکردگی کو بہتر بنا سکتا ہے۔ robots.txt کی ترتیب ہدایات کے ذریعے کی جاتی ہے، جسے ہم مزید دیکھیں گے۔
Robots.txt میں ہدایات ترتیب دینا
صارف ایجنٹ
بنیادی ہدایت کو User-Agent کے نام سے جانا جاتا ہے، جہاں ہم روبوٹس کے لیے ایک خاص کلیدی لفظ مقرر کرتے ہیں۔ اس لفظ کا پتہ لگانے پر، روبوٹ سمجھتا ہے کہ اصول خاص طور پر اس کے لیے ہے۔
robots.txt فائل میں User-Agent استعمال کرنے کی ایک مثال پر غور کریں:
User-Agent: *
Disallow: /private/یہ مثال بتاتی ہے کہ تمام سرچ روبوٹ (علامت "*") میں موجود صفحات کو نظر انداز کرنا چاہئے۔ /نجی/ ڈائریکٹری.
یہاں یہ ہے کہ مخصوص سرچ روبوٹس کے لیے ہدایات کیسی نظر آتی ہیں:
User-Agent: Googlebot
Disallow: /admin/
User-Agent: Bingbot
Disallow: /private/اس صورت میں، Googlebot سرچ روبوٹ کو صفحات کو نظر انداز کرنا چاہیے۔ /ایڈمن/ ڈائریکٹری، جبکہ bingbot میں صفحات کو نظر انداز کرنا چاہئے۔ /نجی/ ڈائریکٹری.
اجازت نہ دیں
اجازت نہ دیں سرچ روبوٹس کو بتاتا ہے کہ ویب سائٹ پر کون سے یو آر ایل کو چھوڑنا ہے یا انڈیکس نہیں کرنا ہے۔ یہ ہدایت اس وقت مفید ہے جب آپ حساس ڈیٹا یا کم معیار کے مواد والے صفحات کو سرچ انجنوں کے ذریعے انڈیکس کیے جانے سے چھپانا چاہتے ہیں۔ اگر robots.txt فائل میں اندراج شامل ہے۔ اجازت نہ دیں: /directory/، پھر روبوٹ کو مخصوص ڈائریکٹری کے مواد تک رسائی سے انکار کردیا جائے گا۔ مثال کے طور پر،
User-agent: *
Disallow: /admin/یہ قدر اس بات کی نشاندہی کرتی ہے۔ تمام روبوٹ سے شروع ہونے والے URLs کو نظر انداز کرنا چاہیے۔ /ایڈمن/. کسی بھی روبوٹ کے ذریعہ پوری سائٹ کو انڈیکس ہونے سے روکنے کے لیے، روٹ ڈائرکٹری کو اصول کے طور پر سیٹ کریں:
User-agent: *
Disallow: /اجازت دیں
"اجازت دیں" کی قدر "Disallow" کے برعکس کام کرتی ہے: یہ سرچ روبوٹس کو کسی مخصوص صفحہ یا ڈائریکٹری تک رسائی کی اجازت دیتی ہے، چاہے robots.txt فائل میں موجود دیگر ہدایات اس تک رسائی کو روکتی ہوں۔
ایک مثال پر غور کریں:
User-agent: *
Disallow: /admin/
Allow: /admin/login.htmlاس مثال میں، یہ واضح کیا گیا ہے کہ روبوٹ کو تک رسائی کی اجازت نہیں ہے۔ /ایڈمن/ ڈائریکٹری، سوائے کے /admin/login.html صفحہ، جو اشاریہ سازی اور اسکیننگ کے لیے دستیاب ہے۔
Robots.txt اور سائٹ کا نقشہ
Sitemap ایک XML فائل ہے جس میں سائٹ پر موجود تمام صفحات اور فائلوں کے URLs کی فہرست ہوتی ہے جنہیں سرچ انجنوں کے ذریعے ترتیب دیا جا سکتا ہے۔ جب کوئی سرچ روبوٹ robots.txt فائل تک رسائی حاصل کرتا ہے اور سائٹ میپ XML فائل کا لنک دیکھتا ہے، تو وہ اس فائل کو سائٹ پر موجود تمام URLs اور وسائل تلاش کرنے کے لیے استعمال کر سکتا ہے۔ ہدایت فارمیٹ میں بیان کی گئی ہے:
Sitemap: https://yoursite.com/filesitemap.xmlیہ اصول عام طور پر دستاویز کے آخر میں کسی مخصوص User-Agent سے منسلک کیے بغیر رکھا جاتا ہے اور بغیر کسی استثناء کے تمام روبوٹ اس پر عملدرآمد کرتے ہیں۔ اگر سائٹ کا مالک sitemap.xml استعمال نہیں کرتا ہے، تو یہ اصول شامل کرنا ضروری نہیں ہے۔
کنفیگرڈ Robots.txt کی مثالیں۔
ورڈپریس کے لیے Robots.txt ترتیب دینا
اس سیکشن میں، ہم ورڈپریس کے لیے ایک ریڈی میڈ کنفیگریشن پر غور کریں گے۔ ہم خفیہ ڈیٹا تک رسائی کو روکنے اور مرکزی صفحات تک رسائی کی اجازت دینے کی تلاش کریں گے۔
ایک تیار حل کے طور پر، آپ درج ذیل کوڈ استعمال کر سکتے ہیں:
User-agent: *
# Block access to files containing confidential data
Disallow: /cgi-bin
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /wp-content/plugins/
Disallow: /wp-content/themes/
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
# Allow access to the main site pages
Allow: /wp-content/uploads/
Allow: /sitemap.xml
Allow: /feed/
Allow: /trackback/
Allow: /comments/feed/
Allow: /category/*/*
Allow: /tag/*
# Prohibit the indexing of old versions of posts and parameterized queries to avoid content duplication or suboptimal indexing.
Disallow: /*?*
Disallow: /?s=*
Disallow: /?p=*
Disallow: /?page_id=*
Disallow: /?cat=*
Disallow: /?tag=*
# Include the sitemap (location needs to be replaced with your own)
Sitemap: http://yourdomain.com/sitemap.xmlاگرچہ تمام ہدایات تبصروں کے ساتھ ہیں، آئیے نتائج کو مزید گہرائی میں دیکھیں۔
- روبوٹ حساس فائلوں اور ڈائریکٹریوں کو انڈیکس نہیں کریں گے۔
- ایک ہی وقت میں، روبوٹ کو سائٹ کے مرکزی صفحات اور وسائل تک رسائی کی اجازت ہے۔
- مواد کی نقل کو روکنے کے لیے پوسٹس کے پرانے ورژنز اور پیرامیٹرائزڈ سوالات پر پابندی لگا دی گئی ہے۔
- بہتر اشاریہ سازی کے لیے سائٹ کے نقشے کی جگہ کی نشاندہی کی گئی ہے۔
اس طرح، ہم نے تیار کنفیگریشن کی ایک عام مثال پر غور کیا ہے، جس میں کچھ حساس فائلیں اور راستے انڈیکسنگ سے پوشیدہ ہیں، لیکن مرکزی ڈائریکٹریز قابل رسائی ہیں۔
بہت سی مشہور CMS یا حسب ضرورت تحریری سائٹس کے برعکس، WordPress کے پاس کئی پلگ ان ہیں جو robots.txt فائل کی تخلیق اور انتظام میں سہولت فراہم کرتے ہیں۔ اس مقصد کے لیے مقبول حل میں سے ایک ہے۔ Yoast کی SEO.
اسے انسٹال کرنے کے لیے، آپ کو یہ کرنے کی ضرورت ہے:
- ورڈپریس ایڈمن پینل پر جائیں۔
- "پلگ انز" سیکشن میں، "نیا شامل کریں" کو منتخب کریں۔
- "Yoast SEO" پلگ ان تلاش کریں اور اسے انسٹال کریں۔
- پلگ ان کو چالو کریں.
robots.txt فائل میں ترمیم کرنے کے لیے، آپ کو:
- ایڈمن پینل کے سائیڈ مینو میں "SEO" سیکشن پر جائیں اور "جنرل" کو منتخب کریں۔
- "ٹولز" ٹیب پر جائیں۔
- "فائلیں" پر کلک کریں۔ یہاں آپ کو مختلف فائلیں نظر آئیں گی، بشمول robots.txt۔
- اپنی ضروریات کے مطابق اشاریہ سازی کے ضروری اصول درج کریں۔
- فائل میں تبدیلیاں کرنے کے بعد، "robots.txt میں تبدیلیاں محفوظ کریں" بٹن پر کلک کریں۔
نوٹ کریں کہ ورڈپریس کے لیے ہر robots.txt فائل کی ترتیب منفرد ہے اور سائٹ کی مخصوص ضروریات اور خصوصیات پر منحصر ہے۔ کوئی عالمگیر ٹیمپلیٹ نہیں ہے جو بغیر کسی استثناء کے تمام وسائل کے مطابق ہو۔ تاہم، یہ مثال اور پلگ ان کا استعمال نمایاں طور پر کام کو آسان بنا سکتا ہے۔
Robots.txt کی دستی ترتیب
اسی طرح، آپ سائٹ کے لیے تیار CMS کی عدم موجودگی میں بھی فائل کی اپنی ترتیب ترتیب دے سکتے ہیں۔ صارف کو robots.txt فائل کو سائٹ کی روٹ ڈائرکٹری میں اپ لوڈ کرنے اور ضروری اصول بتانے کی بھی ضرورت ہے۔ یہاں ان مثالوں میں سے ایک ہے، جس میں تمام دستیاب ہدایات کی نشاندہی کی گئی ہے:
User-agent: *
Disallow: /admin/ # Prohibit access to the administrative panel
Disallow: /secret.html # Prohibit access to a specific file
Disallow: /*.pdf$ # Prohibit indexing of certain file types
Disallow: /*?sort= # Prohibit indexing of certain URL parameters
Allow: /public/ # Allow access to public pages
Sitemap: http://yourdomain.com/sitemap.xml # Include the sitemapRobots.txt فائل کو کیسے چیک کریں۔
غلطیوں کے لیے robots.txt فائل کو چیک کرتے وقت ایک معاون ٹول کے طور پر، آن لائن خدمات استعمال کرنے کی سفارش کی جاتی ہے۔
کی مثال پر غور کریں Yandex ویب ماسٹر سروس چیک کرنے کے لیے، اگر فائل پہلے ہی سرور پر اپ لوڈ ہو چکی ہے تو آپ کو متعلقہ فیلڈ میں اپنی سائٹ کا لنک داخل کرنا ہوگا۔ اس کے بعد، ٹول خود فائل کنفیگریشن کو لوڈ کرے گا۔ کنفیگریشن کو دستی طور پر داخل کرنے کا آپشن بھی ہے:
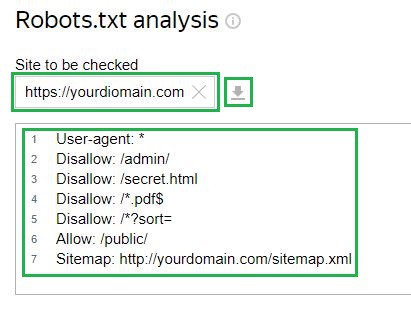
اگلا، آپ کو چیک کی درخواست کرنے اور نتائج کا انتظار کرنے کی ضرورت ہے:
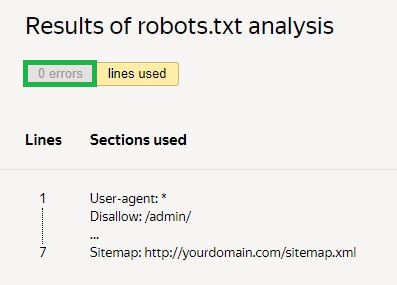
دی گئی مثال میں، کوئی غلطیاں نہیں ہیں۔ اگر کوئی ہے تو، سروس مسائل والے علاقوں اور انہیں ٹھیک کرنے کے طریقے دکھائے گی۔
نتیجہ
خلاصہ میں، ہم نے اس بات پر زور دیا کہ robots.txt فائل سائٹ پر ٹریفک کو کنٹرول کرنے کے لیے کتنی اہم ہے۔ ہم نے مشورہ دیا کہ اسے صحیح طریقے سے ترتیب دینے کے طریقہ کار کو منظم کرنے کے لیے تلاش کے انجن کے صفحات کی فہرست کیسے بنتی ہے۔ اس کے علاوہ، ہم نے اس فائل کو صحیح طریقے سے استعمال کرنے کے طریقے کی مثالیں بھی دیکھیں اور ہدایات دیں کہ یہ کیسے چیک کیا جائے کہ تمام سیٹنگز صحیح طریقے سے کام کر رہی ہیں۔