V tomto článku preskúmame kľúčovú úlohu súboru robots.txt pri riadení návštevnosti webových stránok, prediskutujeme nevyhnutnosť jeho prítomnosti a poskytneme odporúčania na jeho nastavenie pre efektívnu správu indexovania stránok. Okrem toho analyzujeme príklady správneho použitia direktív v súbore robots.txt a poskytneme návod, ako skontrolovať správnosť jeho nastavení.
Prečo je potrebný súbor Robots.txt
Robots.txt je súbor umiestnený na serveri lokality v jej koreňovom adresári. Informuje roboty vyhľadávačov, ako by mali skenovať obsah zdroja. Správne používanie tohto súboru pomáha predchádzať indexovaniu nechcených stránok, chráni dôverné údaje a môže zlepšiť efektivitu SEO optimalizácie a viditeľnosť stránky vo výsledkoch vyhľadávania. Konfigurácia robots.txt sa vykonáva pomocou direktív, na ktoré sa pozrieme ďalej.
Nastavenie smerníc v súbore Robots.txt
User-Agent
Primárna smernica je známa ako User-Agent, kde nastavujeme špeciálne kľúčové slovo pre roboty. Po zistení tohto slova robot pochopí, že pravidlo je určené špeciálne pre neho.
Zvážte príklad použitia User-Agent v súbore robots.txt:
User-Agent: *
Disallow: /private/Tento príklad naznačuje, že všetky vyhľadávacie roboty (reprezentované symbolom "*") by mali ignorovať stránky umiestnené v /súkromné/ adresára.
Pokyny pre konkrétne vyhľadávacie roboty vyzerajú takto:
User-Agent: Googlebot
Disallow: /admin/
User-Agent: Bingbot
Disallow: /private/V tomto prípade Googlebot vyhľadávací robot by mal ignorovať stránky v /admin/ adresár, zatiaľ čo Bingbot by mal ignorovať stránky v /súkromné/ adresára.
neuznať
neuznať informuje vyhľadávacie roboty, ktoré adresy URL majú na webovej lokalite preskočiť alebo neindexovať. Táto smernica je užitočná, keď chcete skryť citlivé údaje alebo stránky s nekvalitným obsahom pred indexovaním vyhľadávacími nástrojmi. Ak súbor robots.txt obsahuje záznam Disallow: /adresár/, potom bude robotom odmietnutý prístup k obsahu zadaného adresára. napr.
User-agent: *
Disallow: /admin/Táto hodnota to naznačuje všetky roboty by mal ignorovať adresy URL začínajúce na /admin/. Ak chcete zablokovať indexovanie celej lokality akýmikoľvek robotmi, nastavte koreňový adresár ako pravidlo:
User-agent: *
Disallow: /povoliť
Hodnota „Povoliť“ pôsobí opačne ako „Zakázať“: umožňuje vyhľadávacím robotom prístup na konkrétnu stránku alebo adresár, aj keď iné príkazy v súbore robots.txt prístup k nim zakazujú.
Zvážte príklad:
User-agent: *
Disallow: /admin/
Allow: /admin/login.htmlV tomto príklade je špecifikované, že roboty nemajú povolený prístup k /admin/ adresár, okrem /admin/login.html stránku, ktorá je k dispozícii na indexovanie a skenovanie.
Robots.txt a súbor Sitemap
Sitemap je súbor XML, ktorý obsahuje zoznam adries URL všetkých stránok a súborov na lokalite, ktoré môžu byť indexované vyhľadávacími nástrojmi. Keď vyhľadávací robot pristúpi k súboru robots.txt a uvidí odkaz na súbor XML mapy lokality, môže tento súbor použiť na nájdenie všetkých dostupných adries URL a zdrojov na stránke. Smernica je špecifikovaná vo formáte:
Sitemap: https://yoursite.com/filesitemap.xmlToto pravidlo je zvyčajne umiestnené na konci dokumentu bez toho, aby bolo viazané na konkrétneho User-Agenta a je spracovávané všetkými robotmi bez výnimky. Ak vlastník stránky nepoužíva sitemap.xml, nie je potrebné pridávať pravidlo.
Príklady súboru Configured Robots.txt
Nastavenie súboru Robots.txt pre WordPress
V tejto časti zvážime hotovú konfiguráciu pre WordPress. Preskúmame blokovanie prístupu k dôverným údajom a umožnenie prístupu na hlavné stránky.
Ako hotové riešenie môžete použiť nasledujúci kód:
User-agent: *
# Block access to files containing confidential data
Disallow: /cgi-bin
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /wp-content/plugins/
Disallow: /wp-content/themes/
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
# Allow access to the main site pages
Allow: /wp-content/uploads/
Allow: /sitemap.xml
Allow: /feed/
Allow: /trackback/
Allow: /comments/feed/
Allow: /category/*/*
Allow: /tag/*
# Prohibit the indexing of old versions of posts and parameterized queries to avoid content duplication or suboptimal indexing.
Disallow: /*?*
Disallow: /?s=*
Disallow: /?p=*
Disallow: /?page_id=*
Disallow: /?cat=*
Disallow: /?tag=*
# Include the sitemap (location needs to be replaced with your own)
Sitemap: http://yourdomain.com/sitemap.xmlAj keď sú všetky smernice sprevádzané komentármi, poďme sa ponoriť hlbšie do záverov.
- Roboty nebudú indexovať citlivé súbory a adresáre.
- Zároveň majú roboty povolený prístup k hlavným stránkam a zdrojom webu.
- ban je nastavený na indexovanie starých verzií príspevkov a parametrizovaných dotazov, aby sa zabránilo duplicite obsahu.
- Umiestnenie mapy lokality je uvedené pre lepšie indexovanie.
Preto sme zvážili všeobecný príklad pripravenej konfigurácie, v ktorej sú niektoré citlivé súbory a cesty skryté pred indexovaním, ale hlavné adresáre sú prístupné.
Na rozdiel od mnohých populárnych CMS alebo na mieru písaných stránok má WordPress niekoľko doplnkov, ktoré uľahčujú vytváranie a správu súboru robots.txt. Jedným z populárnych riešení na tento účel je Yoast SEO.
Ak ju chcete nainštalovať, musíte:
- Prejdite na panel správcu WordPress.
- V časti „Pluginy“ vyberte „Pridať nový“.
- Nájdite doplnok „Yoast SEO“ a nainštalujte ho.
- Aktivujte doplnok.
Ak chcete upraviť súbor robots.txt, musíte:
- Prejdite do sekcie "SEO" v bočnej ponuke panela správcu a vyberte položku "Všeobecné".
- Prejdite na kartu „Nástroje“.
- Kliknite na "Súbory". Tu uvidíte rôzne súbory vrátane robots.txt.
- Zadajte potrebné pravidlá indexovania podľa vašich požiadaviek.
- Po vykonaní zmien v súbore kliknite na tlačidlo „Uložiť zmeny do súboru robots.txt“.
Upozorňujeme, že každé nastavenie súboru robots.txt pre WordPress je jedinečné a závisí od konkrétnych potrieb a funkcií stránky. Neexistuje univerzálna šablóna, ktorá by vyhovovala všetkým zdrojom bez výnimky. Tento príklad a použitie doplnkov však môže výrazne zjednodušiť úlohu.
Manuálne nastavenie súboru Robots.txt
Podobne môžete nastaviť svoju konfiguráciu súboru aj v prípade, že pre stránku nemáte pripravený CMS. Používateľ tiež musí nahrať súbor robots.txt do koreňového adresára stránky a špecifikovať potrebné pravidlá. Tu je jeden z príkladov, v ktorom sú uvedené všetky dostupné smernice:
User-agent: *
Disallow: /admin/ # Prohibit access to the administrative panel
Disallow: /secret.html # Prohibit access to a specific file
Disallow: /*.pdf$ # Prohibit indexing of certain file types
Disallow: /*?sort= # Prohibit indexing of certain URL parameters
Allow: /public/ # Allow access to public pages
Sitemap: http://yourdomain.com/sitemap.xml # Include the sitemapAko skontrolovať súbor Robots.txt
Ako pomocný nástroj pri kontrole chýb v súbore robots.txt sa odporúča použiť online služby.
Zoberme si príklad z Správca webu Yandex služby. Ak chcete skontrolovať, musíte do príslušného poľa vložiť odkaz na vašu stránku, ak je súbor už nahraný na server. Potom samotný nástroj načíta konfiguráciu súboru. Existuje tiež možnosť zadať konfiguráciu manuálne:
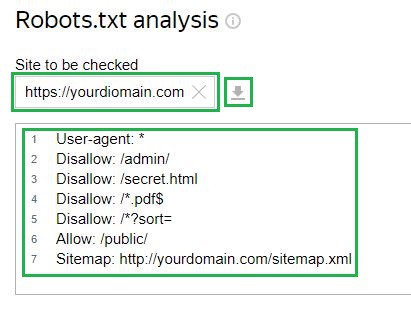
Ďalej musíte požiadať o kontrolu a počkať na výsledky:
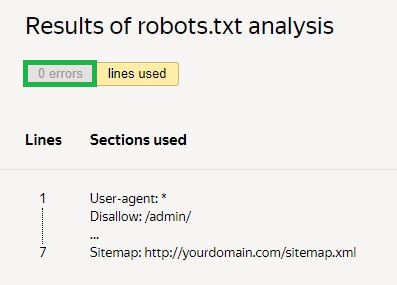
V uvedenom príklade nie sú žiadne chyby. Ak nejaké existujú, služba ukáže problematické oblasti a spôsoby, ako ich opraviť.
Záver
V súhrne sme zdôraznili, aký dôležitý je súbor robots.txt pre kontrolu návštevnosti na stránke. Poskytli sme rady, ako ho správne nastaviť, aby ste spravovali indexovanie stránok vyhľadávačmi. Okrem toho sme sa pozreli aj na príklady, ako správne používať tento súbor a dali sme návod, ako skontrolovať, či všetky nastavenia fungujú správne.