په دې مقاله کې، موږ به د ویب پاڼو د ترافیک په اداره کولو کې د robots.txt فایل کلیدي رول وڅیړو، د هغې د شتون اړتیا په اړه به بحث وکړو، او د مؤثره پاڼې شاخص مدیریت لپاره د هغې د تنظیم کولو لپاره سپارښتنې به وړاندې کړو. سربیره پردې، موږ به د robots.txt فایل کې د سم لارښوونو کارولو مثالونه تحلیل کړو او د هغې د ترتیباتو د سموالي د چک کولو څرنګوالي په اړه لارښود چمتو کړو.
ولې Robots.txt ته اړتیا ده؟
Robots.txt یوه فایل ده چې د سایټ په سرور کې د هغې په روټ ډایرکټرۍ کې موقعیت لري. دا د لټون انجن روبوټونو ته خبر ورکوي چې دوی څنګه باید د سرچینې مینځپانګه سکین کړي. د دې فایل سمه کارول د ناغوښتل شوي پاڼو د شاخص کولو مخنیوي کې مرسته کوي، محرم معلومات ساتي، او کولی شي د SEO اصلاح کولو موثریت او د لټون پایلو کې د سایټ لید ښه کړي. د robots.txt ترتیب د لارښوونو له لارې ترسره کیږي، کوم چې موږ به یې نور وګورو.
په Robots.txt کې د لارښوونو تنظیم کول
کارن استازی
لومړنۍ لارښوونه د کارونکي اجنټ په نوم پیژندل کیږي، چیرې چې موږ د روبوټونو لپاره یو ځانګړی کلیمه ټاکو. د دې کلمې په موندلو سره، روبوټ پوهیږي چې دا قاعده په ځانګړي ډول د هغې لپاره ده.
په robots.txt فایل کې د User-Agent کارولو یوه بیلګه په پام کې ونیسئ:
User-Agent: *
Disallow: /private/دا مثال ښیي چې ټول د لټون روبوټونه (د "" سمبول لخوا استازیتوب کیږي)*") باید هغه پاڼې له پامه وغورځوي چې په /شخصي/ Directory.
دلته د ځانګړو لټون روبوټونو لپاره لارښوونې څنګه ښکاري:
User-Agent: Googlebot
Disallow: /admin/
User-Agent: Bingbot
Disallow: /private/په دې حالت کې، ګوګل د لټون روبوټ باید په پاڼو کې له پامه وغورځوي /اډمین/ ډایرکټري، پداسې حال کې چې bingbot باید په پاڼو کې له پامه وغورځول شي /شخصي/ Directory.
اجازه نه ورکول
اجازه نه ورکول د لټون روبوټونو ته وايي چې کوم URLs باید په ویب پاڼه کې پریښودل شي یا نه. دا لارښوونه ګټوره ده کله چې تاسو غواړئ حساس معلومات یا د ټیټ کیفیت لرونکي مینځپانګې پاڼې د لټون انجنونو لخوا د شاخص کیدو څخه پټ کړئ. که چیرې د robots.txt فایل کې داخله وي اجازه نه ورکول: /directory/، نو روبوټونه به د ټاکل شوي لارښود مینځپانګې ته لاسرسی رد کړي. د مثال په توګه،
User-agent: *
Disallow: /admin/دا ارزښت ښيي چې ټول روباټونه باید هغه URLونه له پامه وغورځوي چې د /اډمین/. د دې لپاره چې ټوله سایټ د هر روبوټ لخوا د انډیکس کیدو څخه مخنیوی وشي، د روټ ډایرکټرۍ د یوې قاعدې په توګه تنظیم کړئ:
User-agent: *
Disallow: /اجازه
د "اجازه" ارزښت د "اجازه نه ورکول" برعکس عمل کوي: دا د لټون روبوټونو ته اجازه ورکوي چې یوې ځانګړې پاڼې یا لارښود ته لاسرسی ومومي، حتی که د robots.txt فایل کې نور لارښوونې ورته لاسرسی منع کړي.
یو مثال په پام کې ونیسئ:
User-agent: *
Disallow: /admin/
Allow: /admin/login.htmlپه دې مثال کې، دا مشخص شوې ده چې روبوټونو ته د لاسرسي اجازه نشته /اډمین/ ډایرکټرۍ، پرته له دې چې /اډمین/لاګ ان.html پاڼه، کوم چې د شاخص کولو او سکین کولو لپاره شتون لري.
Robots.txt او د سایټ نقشه
د سایټ نقشه یو XML فایل دی چې د سایټ د ټولو پاڼو او فایلونو د URLs لیست لري چې د لټون انجنونو لخوا لیست کیدی شي. کله چې د لټون روبوټ د robots.txt فایل ته لاسرسی ومومي او د سایټ نقشې XML فایل ته لینک وګوري، نو دا فایل کولی شي په سایټ کې د ټولو شته URLs او سرچینو موندلو لپاره وکاروي. لارښود په بڼه کې مشخص شوی:
Sitemap: https://yoursite.com/filesitemap.xmlدا قاعده معمولا د سند په پای کې ځای پر ځای کیږي پرته لدې چې د کوم ځانګړي کارونکي اجنټ سره وصل شي او پرته له استثنا د ټولو روبوټونو لخوا پروسس کیږي. که چیرې د سایټ مالک sitemap.xml نه کاروي، نو اړینه نده چې قاعده اضافه کړئ.
د ترتیب شوي Robots.txt مثالونه
د ورڈپریس لپاره د Robots.txt تنظیم کول
پدې برخه کې، موږ به د ورڈپریس لپاره چمتو شوي ترتیب په پام کې ونیسو. موږ به محرم معلوماتو ته د لاسرسي بندولو او اصلي پاڼو ته د لاسرسي اجازه ورکولو په اړه وپلټو.
د چمتو حل په توګه، تاسو کولی شئ لاندې کوډ وکاروئ:
User-agent: *
# Block access to files containing confidential data
Disallow: /cgi-bin
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /wp-content/plugins/
Disallow: /wp-content/themes/
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
# Allow access to the main site pages
Allow: /wp-content/uploads/
Allow: /sitemap.xml
Allow: /feed/
Allow: /trackback/
Allow: /comments/feed/
Allow: /category/*/*
Allow: /tag/*
# Prohibit the indexing of old versions of posts and parameterized queries to avoid content duplication or suboptimal indexing.
Disallow: /*?*
Disallow: /?s=*
Disallow: /?p=*
Disallow: /?page_id=*
Disallow: /?cat=*
Disallow: /?tag=*
# Include the sitemap (location needs to be replaced with your own)
Sitemap: http://yourdomain.com/sitemap.xmlکه څه هم ټول لارښوونې د تبصرو سره مل دي، راځئ چې پایلې ته ژوره کتنه وکړو.
- روباټونه به حساس فایلونه او لارښودونه نه انډیکس کوي.
- په ورته وخت کې، روبوټونو ته د سایټ اصلي پاڼو او سرچینو ته د لاسرسي اجازه ورکول کیږي.
- د منځپانګې د تکرار مخنیوي لپاره د پوسټونو د زړو نسخو او پیرامیټرائز شوي پوښتنو په انډیکس کولو بندیز لګول شوی دی.
- د سایټ نقشې موقعیت د ښه شوي شاخص لپاره ښودل شوی.
په دې توګه، موږ د چمتو شوي ترتیب یوه عمومي بیلګه په پام کې نیولې ده، په کوم کې چې ځینې حساس فایلونه او لارې د شاخص کولو څخه پټې دي، مګر اصلي لارښودونه د لاسرسي وړ دي.
د ډیری مشهور CMS یا دودیز لیکل شوي سایټونو برخلاف، ورڈپریس ډیری پلگ انونه لري چې د robots.txt فایل رامینځته کول او اداره کول اسانه کوي. د دې هدف لپاره یو له مشهورو حلونو څخه دی Yoast SEO.
د دې نصبولو لپاره، تاسو اړتیا لرئ:
- د ورڈپریس اډمین پینل ته لاړ شئ.
- د "پلګ انونو" برخه کې، "نوی اضافه کړئ" غوره کړئ.
- د "Yoast SEO" پلگ ان ومومئ او نصب یې کړئ.
- فلګ فعال کړئ
د robots.txt فایل د سمولو لپاره، تاسو اړتیا لرئ:
- د اډمین پینل د اړخ مینو کې "SEO" برخې ته لاړ شئ او "عمومي" غوره کړئ.
- د "وسیلو" ټب ته لاړ شئ.
- په "فایلونو" کلیک وکړئ. دلته به تاسو مختلف فایلونه وګورئ، په شمول د robots.txt.
- د خپلو اړتیاو سره سم د شاخص کولو اړین قوانین دننه کړئ.
- په فایل کې د بدلونونو راوستلو وروسته، "په robots.txt کې بدلونونه خوندي کړئ" تڼۍ کلیک وکړئ.
په یاد ولرئ چې د ورڈپریس لپاره د هر robots.txt فایل ترتیب ځانګړی دی او د سایټ ځانګړو اړتیاوو او ځانګړتیاو پورې اړه لري. هیڅ نړیوال ټیمپلیټ شتون نلري چې پرته له استثنا ټولو سرچینو سره مناسب وي. په هرصورت، دا مثال او د پلگ انونو کارول کولی شي کار د پام وړ ساده کړي.
د Robots.txt لاسي ترتیب
په ورته ډول، تاسو کولی شئ د فایل ترتیب تنظیم کړئ حتی که چیرې د سایټ لپاره چمتو CMS نه وي. کارونکي هم اړتیا لري چې د robots.txt فایل د سایټ روټ ډایرکټرۍ ته اپلوډ کړي او اړین قواعد مشخص کړي. دلته یو له مثالونو څخه دی، په کوم کې چې ټول شته لارښوونې په ګوته شوي دي:
User-agent: *
Disallow: /admin/ # Prohibit access to the administrative panel
Disallow: /secret.html # Prohibit access to a specific file
Disallow: /*.pdf$ # Prohibit indexing of certain file types
Disallow: /*?sort= # Prohibit indexing of certain URL parameters
Allow: /public/ # Allow access to public pages
Sitemap: http://yourdomain.com/sitemap.xml # Include the sitemapد Robots.txt فایل څنګه وګورئ
د غلطیو لپاره د robots.txt فایل چک کولو پرمهال د مرستندویه وسیلې په توګه، د آنلاین خدماتو کارولو سپارښتنه کیږي.
د مثال په توګه په پام کې ونیسئ د یاندیکس ویب ماسټر خدمت. د چک کولو لپاره، تاسو اړتیا لرئ چې په اړونده ساحه کې خپل سایټ ته لینک داخل کړئ که چیرې فایل دمخه سرور ته اپلوډ شوی وي. له هغې وروسته، وسیله به پخپله د فایل ترتیب پورته کړي. د ترتیب په لاسي ډول د ننوتلو اختیار هم شتون لري:
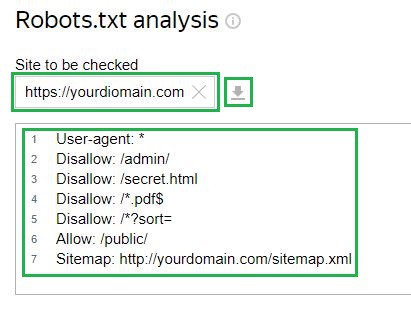
بیا، تاسو اړتیا لرئ چې د چک غوښتنه وکړئ او د پایلو انتظار وکړئ:
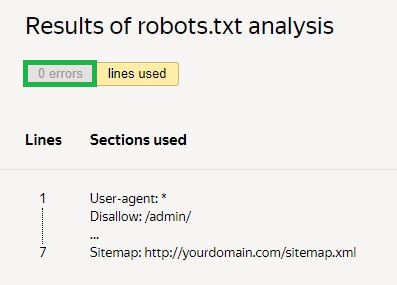
په ورکړل شوي مثال کې، هیڅ غلطۍ نشته. که چیرې کومې وي، نو خدمت به هغه ستونزې او د حل لارې وښيي.
پایله
په لنډه توګه، موږ ټینګار وکړ چې د robots.txt فایل په سایټ کې د ترافیک کنټرول لپاره څومره مهم دی. موږ د دې په اړه مشوره ورکړه چې څنګه یې په سمه توګه تنظیم کړو ترڅو اداره کړو چې څنګه د لټون انجنونه پاڼې شاخص کوي. د دې سربیره، موږ د دې فایل د سم کارولو مثالونه هم وکتل او لارښوونې مو ورکړې چې څنګه وګورو چې ټول ترتیبات په سمه توګه کار کوي.