W tym artykule przyjrzymy się kluczowej roli pliku robots.txt w zarządzaniu ruchem na stronach internetowych, omówimy konieczność jego obecności i przedstawimy zalecenia dotyczące jego konfiguracji w celu efektywnego zarządzania indeksowaniem stron. Ponadto przeanalizujemy przykłady poprawnego użycia dyrektyw w pliku robots.txt i przedstawimy przewodnik, jak sprawdzić poprawność jego ustawień.
Dlaczego plik Robots.txt jest potrzebny
Robots.txt to plik znajdujący się na serwerze witryny w jej katalogu głównym. Informuje roboty wyszukiwarek, w jaki sposób powinny skanować zawartość zasobu. Prawidłowe użycie tego pliku pomaga zapobiegać indeksowaniu niechcianych stron, chroni poufne dane i może poprawić wydajność optymalizacji SEO i widoczność witryny w wynikach wyszukiwania. Konfiguracja pliku robots.txt odbywa się za pomocą dyrektyw, które omówimy dalej.
Ustawianie dyrektyw w pliku Robots.txt
User-Agent
Główna dyrektywa jest znana jako User-Agent, gdzie ustawiamy specjalne słowo kluczowe dla robotów. Po wykryciu tego słowa robot rozumie, że reguła jest przeznaczona specjalnie dla niego.
Rozważmy przykład użycia User-Agent w pliku robots.txt:
User-Agent: *
Disallow: /private/W tym przykładzie wskazano, że wszystkie roboty wyszukiwawcze (reprezentowane symbolem „*") powinien ignorować strony znajdujące się w /prywatny/ katalogiem.
Oto jak wygląda instrukcja dla konkretnych robotów wyszukiwawczych:
User-Agent: Googlebot
Disallow: /admin/
User-Agent: Bingbot
Disallow: /private/W tym przypadku Googlebot robot wyszukiwawczy powinien ignorować strony w /administrator/ katalog, podczas gdy Bingbot należy ignorować strony w /prywatny/ katalogiem.
odrzucać
odrzucać informuje roboty wyszukiwarek, które adresy URL pominąć lub nie indeksować na stronie internetowej. Ta dyrektywa jest przydatna, gdy chcesz ukryć poufne dane lub strony z treścią niskiej jakości przed indeksowaniem przez wyszukiwarki. Jeśli plik robots.txt zawiera wpis Nie zezwalaj: /katalogi/, wówczas robotom zostanie odmówiony dostęp do zawartości określonego katalogu. Na przykład,
User-agent: *
Disallow: /admin/Wartość ta wskazuje, że wszystkie roboty powinien ignorować adresy URL zaczynające się od /administrator/Aby zablokować indeksowanie całej witryny przez roboty, ustaw katalog główny jako regułę:
User-agent: *
Disallow: /Dopuszczać
Wartość „Allow” działa odwrotnie niż „Disallow”: zezwala robotom wyszukiwarek na dostęp do konkretnej strony lub katalogu, nawet jeśli inne dyrektywy w pliku robots.txt zabraniają do nich dostępu.
Rozważmy przykład:
User-agent: *
Disallow: /admin/
Allow: /admin/login.htmlW tym przykładzie określono, że roboty nie mają dostępu do /administrator/ katalog, z wyjątkiem /admin/login.html strona, która jest dostępna do indeksowania i skanowania.
Robots.txt i mapa witryny
Sitemap to plik XML zawierający listę adresów URL wszystkich stron i plików w witrynie, które mogą być indeksowane przez wyszukiwarki. Gdy robot wyszukiwarki uzyskuje dostęp do pliku robots.txt i widzi link do pliku XML sitemap, może użyć tego pliku, aby znaleźć wszystkie dostępne adresy URL i zasoby w witrynie. Dyrektywa jest określona w formacie:
Sitemap: https://yoursite.com/filesitemap.xmlTa reguła jest zwykle umieszczana na końcu dokumentu bez powiązania z konkretnym User-Agent i jest przetwarzana przez wszystkie roboty bez wyjątku. Jeśli właściciel witryny nie używa sitemap.xml, nie ma potrzeby dodawania reguły.
Przykłady skonfigurowanych plików Robots.txt
Konfigurowanie pliku Robots.txt dla WordPressa
W tej sekcji rozważymy gotową konfigurację dla WordPressa. Przyjrzymy się blokowaniu dostępu do poufnych danych i zezwalaniu na dostęp do stron głównych.
Jako gotowe rozwiązanie możesz użyć poniższego kodu:
User-agent: *
# Block access to files containing confidential data
Disallow: /cgi-bin
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /wp-content/plugins/
Disallow: /wp-content/themes/
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
# Allow access to the main site pages
Allow: /wp-content/uploads/
Allow: /sitemap.xml
Allow: /feed/
Allow: /trackback/
Allow: /comments/feed/
Allow: /category/*/*
Allow: /tag/*
# Prohibit the indexing of old versions of posts and parameterized queries to avoid content duplication or suboptimal indexing.
Disallow: /*?*
Disallow: /?s=*
Disallow: /?p=*
Disallow: /?page_id=*
Disallow: /?cat=*
Disallow: /?tag=*
# Include the sitemap (location needs to be replaced with your own)
Sitemap: http://yourdomain.com/sitemap.xmlChoć wszystkie dyrektywy opatrzone są komentarzami, przyjrzyjmy się bliżej wnioskom.
- Roboty nie będą indeksować poufnych plików i katalogów.
- Jednocześnie roboty mają dostęp do głównych stron i zasobów witryny.
- Wprowadzono zakaz indeksowania starych wersji postów i zapytań parametrycznych, aby zapobiec duplikowaniu treści.
- Położenie mapy witryny jest podane w celu usprawnienia indeksowania.
Rozważaliśmy zatem ogólny przykład gotowej konfiguracji, w której niektóre poufne pliki i ścieżki są ukryte przed indeksowaniem, ale główne katalogi są dostępne.
W przeciwieństwie do wielu popularnych CMS-ów lub stron pisanych na zamówienie, WordPress ma kilka wtyczek, które ułatwiają tworzenie i zarządzanie plikiem robots.txt. Jednym z popularnych rozwiązań w tym celu jest Yoast SEO.
Aby zainstalować, należy:
- Przejdź do panelu administracyjnego WordPress.
- W sekcji „Wtyczki” wybierz „Dodaj nową”.
- Znajdź wtyczkę „Yoast SEO” i zainstaluj ją.
- Aktywuj wtyczkę.
Aby edytować plik robots.txt, należy:
- Przejdź do sekcji „SEO” w menu bocznym panelu administracyjnego i wybierz „Ogólne”.
- Przejdź do zakładki „Narzędzia”.
- Kliknij „Pliki”. Tutaj zobaczysz różne pliki, w tym robots.txt.
- Wprowadź wymagane reguły indeksowania zgodnie ze swoimi wymaganiami.
- Po wprowadzeniu zmian w pliku kliknij przycisk „Zapisz zmiany w pliku robots.txt”.
Należy pamiętać, że każde ustawienie pliku robots.txt dla WordPressa jest unikalne i zależy od konkretnych potrzeb i funkcji witryny. Nie ma uniwersalnego szablonu, który pasowałby do wszystkich zasobów bez wyjątku. Jednak ten przykład i użycie wtyczek może znacznie uprościć zadanie.
Ręczne ustawianie pliku Robots.txt
Podobnie możesz skonfigurować plik nawet w przypadku braku gotowego CMS dla witryny. Użytkownik musi również przesłać plik robots.txt do katalogu głównego witryny i określić niezbędne reguły. Oto jeden z przykładów, w którym wskazane są wszystkie dostępne dyrektywy:
User-agent: *
Disallow: /admin/ # Prohibit access to the administrative panel
Disallow: /secret.html # Prohibit access to a specific file
Disallow: /*.pdf$ # Prohibit indexing of certain file types
Disallow: /*?sort= # Prohibit indexing of certain URL parameters
Allow: /public/ # Allow access to public pages
Sitemap: http://yourdomain.com/sitemap.xml # Include the sitemapJak sprawdzić plik Robots.txt
Przy sprawdzaniu pliku robots.txt pod kątem błędów, jako narzędzie pomocnicze, zaleca się skorzystanie z usług online.
Rozważ przykład Yandex Webmaster usługa. Aby to sprawdzić, musisz wstawić link do swojej witryny w odpowiednim polu, jeśli plik jest już przesłany na serwer. Następnie narzędzie samo załaduje konfigurację pliku. Istnieje również opcja ręcznego wprowadzenia konfiguracji:
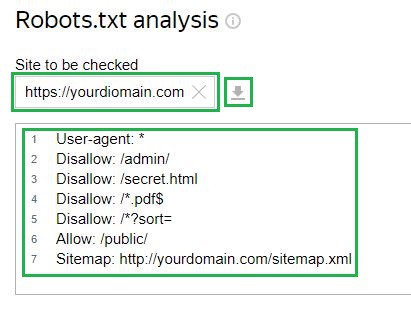
Następnie należy złożyć wniosek o sprawdzenie i czekać na wyniki:
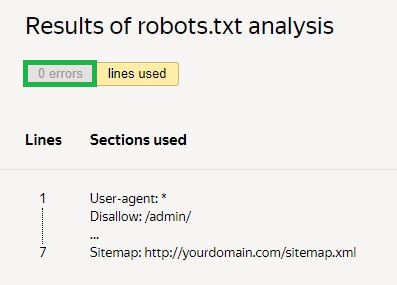
W podanym przykładzie nie ma błędów. Jeśli są, usługa pokaże problematyczne obszary i sposoby ich naprawy.
Wniosek
Podsumowując, podkreśliliśmy, jak ważny jest plik robots.txt dla kontrolowania ruchu na stronie. Doradziliśmy, jak prawidłowo go skonfigurować, aby zarządzać sposobem indeksowania stron przez wyszukiwarki. Ponadto przyjrzeliśmy się przykładom, jak prawidłowo używać tego pliku i podaliśmy instrukcje, jak sprawdzić, czy wszystkie ustawienia działają poprawnie.