I denne artikkelen vil vi undersøke nøkkelrollen til robots.txt-filen i å administrere trafikk på nettsteder, diskutere nødvendigheten av dens tilstedeværelse og gi anbefalinger for å sette den opp for effektiv sideindekseringsadministrasjon. I tillegg vil vi analysere eksempler på riktig bruk av direktiver i robots.txt-filen og gi en veiledning for hvordan du kontrollerer riktigheten av innstillingene.
Hvorfor Robots.txt er nødvendig
Robots.txt er en fil som ligger på nettstedets server i rotkatalogen. Den informerer søkemotorroboter om hvordan de skal skanne innholdet i ressursen. Riktig bruk av denne filen bidrar til å forhindre indeksering av uønskede sider, beskytter konfidensielle data og kan forbedre effektiviteten til SEO-optimalisering og synligheten av nettstedet i søkeresultater. Konfigurasjonen av robots.txt gjøres gjennom direktiver, som vi skal se nærmere på.
Angi direktiver i Robots.txt
User-Agent
Det primære direktivet er kjent som User-Agent, der vi setter et spesielt nøkkelord for roboter. Etter å ha oppdaget dette ordet, forstår roboten at regelen er ment spesielt for det.
Tenk på et eksempel på bruk av User-Agent i robots.txt-filen:
User-Agent: *
Disallow: /private/Dette eksemplet indikerer at alle søkeroboter (representert med symbolet "*") bør ignorere sider som ligger i /privat/ katalogen.
Slik ser instruksjonen ut for spesifikke søkeroboter:
User-Agent: Googlebot
Disallow: /admin/
User-Agent: Bingbot
Disallow: /private/I dette tilfellet er det Googlebot søkerobot bør ignorere sider i /admin/ katalog, mens Bingbot bør ignorere sider i /privat/ katalogen.
forby
forby forteller søkeroboter hvilke URL-er som skal hoppes over eller ikke indekseres på nettstedet. Dette direktivet er nyttig når du vil skjule sensitive data eller innholdssider av lav kvalitet fra å bli indeksert av søkemotorer. Hvis robots.txt-filen inneholder oppføringen Disallow: /kataloger/, vil roboter bli nektet tilgang til innholdet i den angitte katalogen. For eksempel
User-agent: *
Disallow: /admin/Denne verdien indikerer det alle roboter bør ignorere nettadresser som begynner med /admin/. For å blokkere hele nettstedet fra å bli indeksert av noen roboter, angi rotkatalogen som en regel:
User-agent: *
Disallow: /Allow
"Allow"-verdien virker motsatt av "Disallow": den tillater søkeroboter tilgang til en bestemt side eller katalog, selv om andre direktiver i robots.txt-filen forbyr tilgang til den.
Tenk på et eksempel:
User-agent: *
Disallow: /admin/
Allow: /admin/login.htmlI dette eksemplet er det spesifisert at roboter ikke har tilgang til /admin/ katalogen, bortsett fra /admin/login.html side, som er tilgjengelig for indeksering og skanning.
Robots.txt og Sitemap
Sitemap er en XML-fil som inneholder en liste over URL-er til alle sider og filer på nettstedet som kan indekseres av søkemotorer. Når en søkerobot får tilgang til robots.txt-filen og ser en lenke til en sitemap XML-fil, kan den bruke denne filen til å finne alle tilgjengelige URL-er og ressurser på nettstedet. Direktivet er spesifisert i formatet:
Sitemap: https://yoursite.com/filesitemap.xmlDenne regelen plasseres vanligvis på slutten av dokumentet uten å være knyttet til en spesifikk brukeragent og behandles av alle roboter uten unntak. Hvis nettstedeieren ikke bruker sitemap.xml, er det ikke nødvendig å legge til regelen.
Eksempler på konfigurerte Robots.txt
Sette opp Robots.txt for WordPress
I denne delen vil vi vurdere en ferdig konfigurasjon for WordPress. Vi vil utforske blokkering av tilgang til konfidensielle data og tillate tilgang til hovedsidene.
Som en klar løsning kan du bruke følgende kode:
User-agent: *
# Block access to files containing confidential data
Disallow: /cgi-bin
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /wp-content/plugins/
Disallow: /wp-content/themes/
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
# Allow access to the main site pages
Allow: /wp-content/uploads/
Allow: /sitemap.xml
Allow: /feed/
Allow: /trackback/
Allow: /comments/feed/
Allow: /category/*/*
Allow: /tag/*
# Prohibit the indexing of old versions of posts and parameterized queries to avoid content duplication or suboptimal indexing.
Disallow: /*?*
Disallow: /?s=*
Disallow: /?p=*
Disallow: /?page_id=*
Disallow: /?cat=*
Disallow: /?tag=*
# Include the sitemap (location needs to be replaced with your own)
Sitemap: http://yourdomain.com/sitemap.xmlSelv om alle direktiver er ledsaget av kommentarer, la oss gå dypere inn i konklusjonene.
- Roboter vil ikke indeksere sensitive filer og kataloger.
- Samtidig får roboter tilgang til hovedsidene og ressursene på nettstedet.
- ban er satt til å indeksere gamle versjoner av innlegg og parameteriserte spørringer for å forhindre duplisering av innhold.
- Plasseringen av nettstedskartet er angitt for forbedret indeksering.
Derfor har vi vurdert et generelt eksempel på en klar konfigurasjon, der noen sensitive filer og stier er skjult fra indeksering, men hovedkatalogene er tilgjengelige.
I motsetning til mange populære CMS eller spesialskrevne nettsteder, har WordPress flere plugins som forenkler opprettelsen og administrasjonen av robots.txt-filen. En av de populære løsningene for dette formålet er Yoast SEO.
For å installere det, må du:
- Gå til WordPress-administrasjonspanelet.
- I delen "Plugins" velger du "Legg til ny".
- Finn "Yoast SEO"-plugin og installer den.
- Aktiver plugin.
For å redigere robots.txt-filen må du:
- Gå til "SEO"-delen i administrasjonspanelets sidemeny og velg "Generelt".
- Gå til "Verktøy"-fanen.
- Klikk på "Filer". Her vil du se ulike filer, inkludert robots.txt.
- Angi de nødvendige indekseringsreglene i henhold til dine krav.
- Etter å ha gjort endringer i filen, klikk på "Lagre endringer i robots.txt"-knappen.
Merk at hver robots.txt-filinnstilling for WordPress er unik og avhenger av de spesifikke behovene og funksjonene til nettstedet. Det er ingen universell mal som vil passe alle ressurser uten unntak. Dette eksemplet og bruken av plugins kan imidlertid forenkle oppgaven betydelig.
Manuell innstilling av Robots.txt
På samme måte kan du sette opp konfigurasjonen av filen selv i fravær av en klar CMS for nettstedet. Brukeren må også laste opp robots.txt-filen til rotkatalogen til nettstedet og spesifisere de nødvendige reglene. Her er ett av eksemplene, der alle tilgjengelige direktiver er angitt:
User-agent: *
Disallow: /admin/ # Prohibit access to the administrative panel
Disallow: /secret.html # Prohibit access to a specific file
Disallow: /*.pdf$ # Prohibit indexing of certain file types
Disallow: /*?sort= # Prohibit indexing of certain URL parameters
Allow: /public/ # Allow access to public pages
Sitemap: http://yourdomain.com/sitemap.xml # Include the sitemapHvordan sjekke Robots.txt-filen
Som et hjelpeverktøy når du sjekker robots.txt-filen for feil, anbefales det å bruke nettjenester.
Tenk på eksemplet på Yandex Webmaster service. For å sjekke, må du sette inn en lenke til nettstedet ditt i det tilsvarende feltet hvis filen allerede er lastet opp til serveren. Etter det vil verktøyet selv laste inn filkonfigurasjonen. Det er også en mulighet for å legge inn konfigurasjonen manuelt:
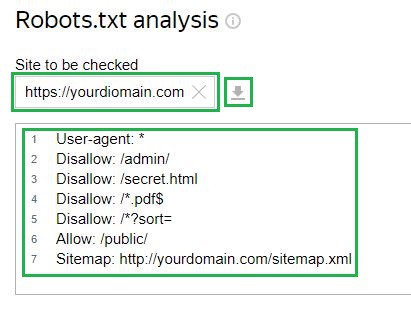
Deretter må du be om en sjekk og vente på resultatene:
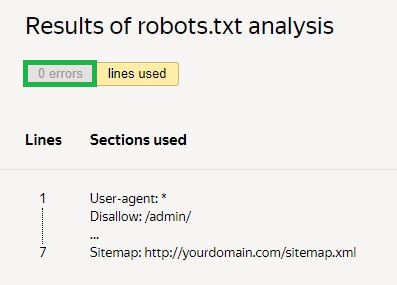
I det gitte eksemplet er det ingen feil. Hvis det er noen, vil tjenesten vise de problematiske områdene og måter å fikse dem på.
Konklusjon
Oppsummert la vi vekt på hvor viktig robots.txt-filen er for å kontrollere trafikken på nettstedet. Vi ga råd om hvordan du konfigurerer det riktig for å administrere hvordan søkemotorer indekserer sider. I tillegg til dette har vi også sett på eksempler på hvordan du bruker denne filen riktig og ga instruksjoner om hvordan du sjekker at alle innstillinger fungerer som de skal.