Dalam artikel ini, kami akan mengkaji peranan utama fail robots.txt dalam mengurus trafik di tapak web, membincangkan keperluan kehadirannya dan memberikan pengesyoran untuk menyediakannya bagi pengurusan pengindeksan halaman yang berkesan. Selain itu, kami akan menganalisis contoh penggunaan arahan yang betul dalam fail robots.txt dan memberikan panduan tentang cara menyemak ketepatan tetapannya.
Mengapa Robots.txt Diperlukan
Robots.txt ialah fail yang terletak pada pelayan tapak dalam direktori akarnya. Ia memberitahu robot enjin carian bagaimana mereka harus mengimbas kandungan sumber. Penggunaan fail ini dengan betul membantu menghalang pengindeksan halaman yang tidak diingini, melindungi data sulit dan boleh meningkatkan kecekapan pengoptimuman SEO dan keterlihatan tapak dalam hasil carian. Konfigurasi robots.txt dilakukan melalui arahan, yang akan kita lihat lebih lanjut.
Menetapkan Arahan dalam Robots.txt
Ejen Pengguna
Arahan utama dikenali sebagai User-Agent, di mana kami menetapkan kata kunci khas untuk robot. Setelah mengesan perkataan ini, robot memahami bahawa peraturan itu ditujukan khusus untuknya.
Pertimbangkan contoh menggunakan User-Agent dalam fail robots.txt:
User-Agent: *
Disallow: /private/Contoh ini menunjukkan bahawa semua robot carian (diwakili oleh simbol "*") harus mengabaikan halaman yang terletak di /swasta/ direktori.
Begini cara arahan mencari robot carian tertentu:
User-Agent: Googlebot
Disallow: /admin/
User-Agent: Bingbot
Disallow: /private/Dalam kes ini, yang Googlebot robot carian harus mengabaikan halaman dalam /admin/ direktori, manakala Bingbot harus mengabaikan halaman dalam /swasta/ direktori.
tidak membenarkan
tidak membenarkan memberitahu robot carian URL mana yang hendak dilangkau atau tidak diindeks di tapak web. Arahan ini berguna apabila anda ingin menyembunyikan data sensitif atau halaman kandungan berkualiti rendah daripada diindeks oleh enjin carian. Jika fail robots.txt mengandungi entri Tolak: /direktori/, maka robot akan dinafikan akses kepada kandungan direktori yang ditentukan. Sebagai contoh,
User-agent: *
Disallow: /admin/Nilai ini menunjukkan bahawa semua robot harus mengabaikan URL bermula dengan /admin/. Untuk menyekat keseluruhan tapak daripada diindeks oleh mana-mana robot, tetapkan direktori akar sebagai peraturan:
User-agent: *
Disallow: /Benarkan
Nilai "Benarkan" bertindak bertentangan dengan "Larang": ia membenarkan robot carian mengakses halaman atau direktori tertentu, walaupun arahan lain dalam fail robots.txt melarang akses kepadanya.
Pertimbangkan contoh:
User-agent: *
Disallow: /admin/
Allow: /admin/login.htmlDalam contoh ini, dinyatakan bahawa robot tidak dibenarkan akses kepada /admin/ direktori, kecuali untuk /admin/login.html halaman, yang tersedia untuk pengindeksan dan pengimbasan.
Robots.txt dan Peta Laman
Peta laman ialah fail XML yang mengandungi senarai URL semua halaman dan fail pada tapak yang boleh diindeks oleh enjin carian. Apabila robot carian mengakses fail robots.txt dan melihat pautan ke fail XML peta laman, ia boleh menggunakan fail ini untuk mencari semua URL dan sumber yang tersedia di tapak. Arahan dinyatakan dalam format:
Sitemap: https://yoursite.com/filesitemap.xmlPeraturan ini biasanya diletakkan di penghujung dokumen tanpa terikat dengan Agen Pengguna tertentu dan diproses oleh semua robot tanpa pengecualian. Jika pemilik tapak tidak menggunakan sitemap.xml, anda tidak perlu menambah peraturan.
Contoh Configured Robots.txt
Menyediakan Robots.txt untuk WordPress
Dalam bahagian ini, kami akan mempertimbangkan konfigurasi siap sedia untuk WordPress. Kami akan meneroka menyekat akses kepada data sulit dan membenarkan akses kepada halaman utama.
Sebagai penyelesaian sedia, anda boleh menggunakan kod berikut:
User-agent: *
# Block access to files containing confidential data
Disallow: /cgi-bin
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /wp-content/plugins/
Disallow: /wp-content/themes/
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
# Allow access to the main site pages
Allow: /wp-content/uploads/
Allow: /sitemap.xml
Allow: /feed/
Allow: /trackback/
Allow: /comments/feed/
Allow: /category/*/*
Allow: /tag/*
# Prohibit the indexing of old versions of posts and parameterized queries to avoid content duplication or suboptimal indexing.
Disallow: /*?*
Disallow: /?s=*
Disallow: /?p=*
Disallow: /?page_id=*
Disallow: /?cat=*
Disallow: /?tag=*
# Include the sitemap (location needs to be replaced with your own)
Sitemap: http://yourdomain.com/sitemap.xmlWalaupun semua arahan disertakan dengan komen, mari kita mendalami kesimpulannya dengan lebih mendalam.
- Robot tidak akan mengindeks fail dan direktori sensitif.
- Pada masa yang sama, robot dibenarkan mengakses halaman utama dan sumber tapak.
- larangan ditetapkan untuk mengindeks versi lama siaran dan pertanyaan berparameter untuk mengelakkan pertindihan kandungan.
- Lokasi peta laman ditunjukkan untuk pengindeksan yang lebih baik.
Oleh itu, kami telah mempertimbangkan contoh umum konfigurasi sedia, di mana beberapa fail dan laluan sensitif disembunyikan daripada pengindeksan, tetapi direktori utama boleh diakses.
Tidak seperti kebanyakan laman web CMS atau tulisan tersuai yang popular, WordPress mempunyai beberapa pemalam yang memudahkan penciptaan dan pengurusan fail robots.txt. Salah satu penyelesaian yang popular untuk tujuan ini ialah Yoast SEO.
Untuk memasangnya, anda perlu:
- Pergi ke panel pentadbir WordPress.
- Dalam bahagian "Pemalam", pilih "Tambah Baharu".
- Cari pemalam "Yoast SEO" dan pasangkannya.
- Aktifkan pemalam.
Untuk mengedit fail robots.txt, anda perlu:
- Pergi ke bahagian "SEO" dalam menu sisi panel pentadbir dan pilih "Umum".
- Pergi ke tab "Alat".
- Klik pada "Fail". Di sini anda akan melihat pelbagai fail, termasuk robots.txt.
- Masukkan peraturan pengindeksan yang diperlukan mengikut keperluan anda.
- Selepas membuat perubahan pada fail, klik butang "Simpan perubahan pada robots.txt".
Ambil perhatian bahawa setiap tetapan fail robots.txt untuk WordPress adalah unik dan bergantung pada keperluan dan ciri khusus tapak. Tiada templat universal yang sesuai dengan semua sumber tanpa pengecualian. Walau bagaimanapun, contoh ini dan penggunaan pemalam boleh memudahkan tugas dengan ketara.
Tetapan Manual Robots.txt
Begitu juga, anda boleh menyediakan konfigurasi fail anda walaupun tanpa CMS sedia untuk tapak. Pengguna juga perlu memuat naik fail robots.txt ke direktori akar tapak dan menentukan peraturan yang diperlukan. Berikut ialah salah satu contoh, di mana semua arahan yang tersedia ditunjukkan:
User-agent: *
Disallow: /admin/ # Prohibit access to the administrative panel
Disallow: /secret.html # Prohibit access to a specific file
Disallow: /*.pdf$ # Prohibit indexing of certain file types
Disallow: /*?sort= # Prohibit indexing of certain URL parameters
Allow: /public/ # Allow access to public pages
Sitemap: http://yourdomain.com/sitemap.xml # Include the sitemapCara Semak Fail Robots.txt
Sebagai alat bantu semasa menyemak fail robots.txt untuk mencari ralat, adalah disyorkan untuk menggunakan perkhidmatan dalam talian.
Pertimbangkan contoh Juruweb Yandex perkhidmatan. Untuk menyemak, anda perlu memasukkan pautan ke tapak anda dalam medan yang sepadan jika fail telah dimuat naik ke pelayan. Selepas itu, alat itu sendiri akan memuatkan konfigurasi fail. Terdapat juga pilihan untuk memasukkan konfigurasi secara manual:
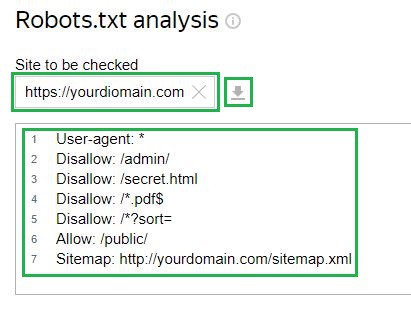
Seterusnya, anda perlu meminta semakan dan tunggu keputusan:
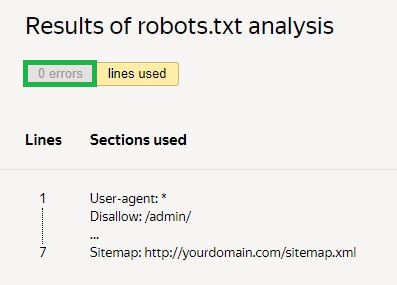
Dalam contoh yang diberikan, tiada ralat. Jika ada, perkhidmatan akan menunjukkan kawasan yang bermasalah dan cara untuk membetulkannya.
Kesimpulan
Ringkasnya, kami menekankan betapa pentingnya fail robots.txt untuk mengawal trafik di tapak. Kami memberikan nasihat tentang cara menyediakannya dengan betul untuk mengurus cara enjin carian mengindeks halaman. Di samping itu, kami juga melihat contoh cara menggunakan fail ini dengan betul dan memberi arahan tentang cara menyemak bahawa semua tetapan berfungsi dengan betul.