In questo articolo, esamineremo il ruolo chiave del file robots.txt nella gestione del traffico sui siti Web, discuteremo la necessità della sua presenza e forniremo raccomandazioni per impostarlo per una gestione efficace dell'indicizzazione delle pagine. Inoltre, analizzeremo esempi di utilizzo corretto delle direttive nel file robots.txt e forniremo una guida su come verificare la correttezza delle sue impostazioni.
Perché Robots.txt è necessario
Robots.txt è un file che si trova sul server del sito nella sua directory principale. Informa i robot dei motori di ricerca su come dovrebbero analizzare il contenuto della risorsa. L'uso corretto di questo file aiuta a prevenire l'indicizzazione di pagine indesiderate, protegge i dati riservati e può migliorare l'efficienza dell'ottimizzazione SEO e la visibilità del sito nei risultati di ricerca. La configurazione di robots.txt avviene tramite direttive, che esamineremo più avanti.
Impostazione delle direttive in Robots.txt
User-Agent
La direttiva primaria è nota come User-Agent, dove impostiamo una parola chiave speciale per i robot. Quando rileva questa parola, il robot capisce che la regola è pensata specificamente per lui.
Consideriamo un esempio di utilizzo di User-Agent nel file robots.txt:
User-Agent: *
Disallow: /private/Questo esempio indica che tutti i robot di ricerca (rappresentati dal simbolo "*") dovrebbe ignorare le pagine situate in /privato/ directory.
Ecco come appaiono le istruzioni per specifici robot di ricerca:
User-Agent: Googlebot
Disallow: /admin/
User-Agent: Bingbot
Disallow: /private/In questo caso, il Googlebot il robot di ricerca dovrebbe ignorare le pagine in /amministratore/ directory, mentre Bingbot dovrebbe ignorare le pagine in /privato/ directory.
rifiutare
rifiutare indica ai robot di ricerca quali URL saltare o non indicizzare sul sito web. Questa direttiva è utile quando si desidera nascondere dati sensibili o pagine di contenuti di bassa qualità dall'indicizzazione da parte dei motori di ricerca. Se il file robots.txt contiene la voce Non consentire: /directory/, ai robot verrà negato l'accesso al contenuto della directory specificata. Ad esempio,
User-agent: *
Disallow: /admin/Questo valore indica che tutti i robot dovrebbe ignorare gli URL che iniziano con /amministratore/Per impedire che l'intero sito venga indicizzato da qualsiasi robot, imposta la directory principale come regola:
User-agent: *
Disallow: /Consentire
Il valore "Allow" agisce in modo opposto a "Disallow": consente ai robot di ricerca di accedere a una pagina o directory specifica, anche se altre direttive nel file robots.txt ne proibiscono l'accesso.
Considera un esempio:
User-agent: *
Disallow: /admin/
Allow: /admin/login.htmlIn questo esempio, viene specificato che ai robot non è consentito l'accesso al /amministratore/ directory, ad eccezione di /admin/accesso.html pagina disponibile per l'indicizzazione e la scansione.
Robots.txt e mappa del sito
Sitemap è un file XML che contiene un elenco di URL di tutte le pagine e i file del sito che possono essere indicizzati dai motori di ricerca. Quando un robot di ricerca accede al file robots.txt e vede un collegamento a un file XML sitemap, può usare questo file per trovare tutti gli URL e le risorse disponibili sul sito. La direttiva è specificata nel formato:
Sitemap: https://yoursite.com/filesitemap.xmlQuesta regola è solitamente posizionata alla fine del documento senza essere legata a uno specifico User-Agent e viene elaborata da tutti i robot senza eccezioni. Se il proprietario del sito non utilizza sitemap.xml, non è necessario aggiungere la regola.
Esempi di Robots.txt configurato
Impostazione di Robots.txt per WordPress
In questa sezione, prenderemo in considerazione una configurazione pronta all'uso per WordPress. Esploreremo il blocco dell'accesso ai dati riservati e il permesso di accesso alle pagine principali.
Come soluzione pronta, puoi utilizzare il seguente codice:
User-agent: *
# Block access to files containing confidential data
Disallow: /cgi-bin
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /wp-content/plugins/
Disallow: /wp-content/themes/
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
# Allow access to the main site pages
Allow: /wp-content/uploads/
Allow: /sitemap.xml
Allow: /feed/
Allow: /trackback/
Allow: /comments/feed/
Allow: /category/*/*
Allow: /tag/*
# Prohibit the indexing of old versions of posts and parameterized queries to avoid content duplication or suboptimal indexing.
Disallow: /*?*
Disallow: /?s=*
Disallow: /?p=*
Disallow: /?page_id=*
Disallow: /?cat=*
Disallow: /?tag=*
# Include the sitemap (location needs to be replaced with your own)
Sitemap: http://yourdomain.com/sitemap.xmlSebbene tutte le direttive siano accompagnate da commenti, approfondiamo le conclusioni.
- I robot non indicizzeranno file e directory sensibili.
- Allo stesso tempo, ai robot è consentito l'accesso alle pagine principali e alle risorse del sito.
- è vietato indicizzare vecchie versioni di post e query parametriche per impedire la duplicazione dei contenuti.
- Per migliorare l'indicizzazione, viene indicata la posizione della mappa del sito.
Abbiamo quindi preso in considerazione un esempio generale di configurazione pronta, in cui alcuni file e percorsi sensibili sono nascosti all'indicizzazione, ma le directory principali sono accessibili.
A differenza di molti CMS popolari o siti scritti su misura, WordPress ha diversi plugin che facilitano la creazione e la gestione del file robots.txt. Una delle soluzioni più diffuse a questo scopo è Yoast SEO.
Per installarlo è necessario:
- Vai al pannello di amministrazione di WordPress.
- Nella sezione "Plugin", seleziona "Aggiungi nuovo".
- Trova il plugin "Yoast SEO" e installalo.
- Attiva il plugin.
Per modificare il file robots.txt, è necessario:
- Vai alla sezione "SEO" nel menu laterale del pannello di amministrazione e seleziona "Generale".
- Vai alla scheda "Strumenti".
- Fare clic su "File". Qui verranno visualizzati vari file, tra cui robots.txt.
- Inserisci le regole di indicizzazione necessarie in base alle tue esigenze.
- Dopo aver apportato le modifiche al file, fare clic sul pulsante "Salva modifiche al file robots.txt".
Si noti che ogni impostazione del file robots.txt per WordPress è unica e dipende dalle esigenze e dalle caratteristiche specifiche del sito. Non esiste un modello universale che si adatti a tutte le risorse senza eccezioni. Tuttavia, questo esempio e l'uso di plugin possono semplificare notevolmente il compito.
Impostazione manuale di Robots.txt
Allo stesso modo, puoi impostare la configurazione del file anche in assenza di un CMS pronto per il sito. L'utente deve anche caricare il file robots.txt nella directory principale del sito e specificare le regole necessarie. Ecco uno degli esempi, in cui sono indicate tutte le direttive disponibili:
User-agent: *
Disallow: /admin/ # Prohibit access to the administrative panel
Disallow: /secret.html # Prohibit access to a specific file
Disallow: /*.pdf$ # Prohibit indexing of certain file types
Disallow: /*?sort= # Prohibit indexing of certain URL parameters
Allow: /public/ # Allow access to public pages
Sitemap: http://yourdomain.com/sitemap.xml # Include the sitemapCome controllare il file Robots.txt
Come strumento ausiliario per verificare la presenza di errori nel file robots.txt, si consiglia di utilizzare i servizi online.
Considera l'esempio di Webmaster di Yandex servizio. Per controllare, devi inserire un collegamento al tuo sito nel campo corrispondente se il file è già caricato sul server. Dopodiché, lo strumento stesso caricherà la configurazione del file. C'è anche un'opzione per inserire manualmente la configurazione:
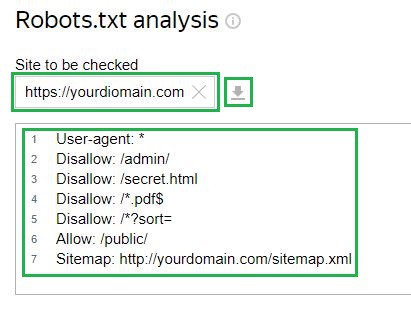
Successivamente, è necessario richiedere un controllo e attendere i risultati:
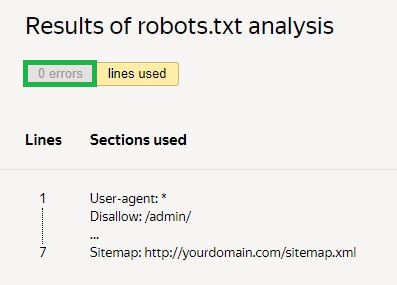
Nell'esempio dato, non ci sono errori. Se ce ne sono, il servizio mostrerà le aree problematiche e i modi per risolverle.
Conclusione
In sintesi, abbiamo sottolineato quanto sia importante il file robots.txt per controllare il traffico sul sito. Abbiamo fornito consigli su come impostarlo correttamente per gestire il modo in cui i motori di ricerca indicizzano le pagine. Oltre a questo, abbiamo anche esaminato esempi di come utilizzare correttamente questo file e fornito istruzioni su come verificare che tutte le impostazioni funzionino correttamente.