У гэтым артыкуле мы разгледзім ключавую ролю файла robots.txt у кіраванні трафікам на сайтах, абмяркуем неабходнасць яго прысутнасці і дамо рэкамендацыі па яго наладзе для эфектыўнага кіравання індэксаваннем старонак. Акрамя таго, мы прааналізуем прыклады правільнага выкарыстання дырэктыў у файле robots.txt і дамо інструкцыю па праверцы правільнасці яго налад.
Навошта патрэбен файл robots.txt
Robots.txt - гэта файл, размешчаны на серверы сайта ў яго каранёвым каталогу. Ён інфармуе пошукавых робатаў аб тым, як яны павінны сканаваць кантэнт рэсурсу. Правільнае выкарыстанне гэтага файла дапамагае прадухіліць індэксацыю непажаданых старонак, абараняе канфідэнцыяльныя даныя і можа палепшыць эфектыўнасць аптымізацыі SEO і бачнасць сайта ў выніках пошуку. Канфігурацыя robots.txt ажыццяўляецца праз дырэктывы, якія мы разгледзім далей.
Налада дырэктываў у Robots.txt
Карыстальнік
Асноўная дырэктыва вядомая як User-Agent, дзе мы ўсталёўваем спецыяльнае ключавое слова для робатаў. Выявіўшы гэтае слова, робат разумее, што правіла прызначана менавіта для яго.
Разгледзім прыклад выкарыстання User-Agent у файле robots.txt:
User-Agent: *
Disallow: /private/Гэты прыклад паказвае, што ўсе пошукавыя робаты (прадстаўленыя сімвалам "*") павінны ігнараваць старонкі, размешчаныя ў /прыватны/ каталог.
Вось як выглядае інструкцыя для канкрэтных пошукавых робатаў:
User-Agent: Googlebot
Disallow: /admin/
User-Agent: Bingbot
Disallow: /private/У гэтым выпадку, Googlebot пошукавы робат павінен ігнараваць старонкі ў /адміністратар/ каталог, пакуль Bingbot павінны ігнараваць старонкі ў /прыватны/ каталог.
Disallow
Disallow паведамляе пошукавым робатам, якія URL прапускаць ці не індэксаваць на сайце. Гэтая дырэктыва карысная, калі вы хочаце схаваць канфідэнцыяльныя даныя або старонкі нізкай якасці змесціва ад індэксацыі пошукавымі сістэмамі. Калі файл robots.txt змяшчае запіс Забараніць: /каталогі/, то робатам будзе забаронены доступ да змесціва названага каталога. напрыклад,
User-agent: *
Disallow: /admin/Гэта значэнне паказвае на тое усе робаты павінны ігнараваць URL-адрасы, якія пачынаюцца з /адміністратар/. Каб заблакаваць увесь сайт ад індэксацыі любымі робатамі, усталюйце каранёвы каталог як правіла:
User-agent: *
Disallow: /Дазваляць
Значэнне "Дазволіць" дзейнічае супрацьлегла "Забараніць": яно дазваляе пошукавым робатам доступ да пэўнай старонкі або каталога, нават калі іншыя дырэктывы ў файле robots.txt забараняюць доступ да іх.
Разгледзім прыклад:
User-agent: *
Disallow: /admin/
Allow: /admin/login.htmlУ гэтым прыкладзе паказана, што робатам забаронены доступ да /адміністратар/ каталог, за выключэннем /admin/login.html старонка, якая даступная для індэксацыі і сканавання.
Robots.txt і карта сайта
Карта сайта - гэта файл XML, які змяшчае спіс URL-адрасоў усіх старонак і файлаў на сайце, якія могуць быць праіндэксаваныя пошукавымі сістэмамі. Калі пошукавы робат атрымлівае доступ да файла robots.txt і бачыць спасылку на XML-файл карты сайта, ён можа выкарыстоўваць гэты файл для пошуку ўсіх даступных URL-адрасоў і рэсурсаў на сайце. Дырэктыва вызначаецца ў фармаце:
Sitemap: https://yoursite.com/filesitemap.xmlЗвычайна гэта правіла змяшчаецца ў канцы дакумента без прывязкі да канкрэтнага User-Agent і апрацоўваецца ўсімі робатамі без выключэння. Калі ўладальнік сайта не выкарыстоўвае sitemap.xml, правіла дадаваць не трэба.
Прыклады сканфігураванага Robots.txt
Настройка Robots.txt для WordPress
У гэтым раздзеле мы разгледзім гатовую канфігурацыю для WordPress. Мы вывучым блакіроўку доступу да канфідэнцыйных даных і дазвол доступу да галоўных старонак.
У якасці гатовага рашэння можна выкарыстоўваць наступны код:
User-agent: *
# Block access to files containing confidential data
Disallow: /cgi-bin
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /wp-content/plugins/
Disallow: /wp-content/themes/
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
# Allow access to the main site pages
Allow: /wp-content/uploads/
Allow: /sitemap.xml
Allow: /feed/
Allow: /trackback/
Allow: /comments/feed/
Allow: /category/*/*
Allow: /tag/*
# Prohibit the indexing of old versions of posts and parameterized queries to avoid content duplication or suboptimal indexing.
Disallow: /*?*
Disallow: /?s=*
Disallow: /?p=*
Disallow: /?page_id=*
Disallow: /?cat=*
Disallow: /?tag=*
# Include the sitemap (location needs to be replaced with your own)
Sitemap: http://yourdomain.com/sitemap.xmlНягледзячы на тое, што ўсе дырэктывы суправаджаюцца каментарамі, спынімся на высновах.
- Робаты не будуць індэксаваць канфідэнцыяльныя файлы і каталогі.
- Пры гэтым робатам дазваляецца доступ да галоўных старонак і рэсурсаў сайта.
- усталяваны забарона на індэксаванне старых версій паведамленняў і параметрізаваных запытаў для прадухілення дублявання кантэнту.
- Месцазнаходжанне карты сайта паказана для паляпшэння індэксацыі.
Такім чынам, мы разгледзелі агульны прыклад гатовай канфігурацыі, у якой некаторыя канфідэнцыйныя файлы і шляхі схаваныя ад індэксацыі, але асноўныя каталогі даступныя.
У адрозненне ад многіх папулярных CMS або сайтаў, напісаных на заказ, WordPress мае некалькі ўбудоў, якія палягчаюць стварэнне і кіраванне файлам robots.txt. Адным з папулярных рашэнняў для гэтай мэты з'яўляецца Yoast SEO.
Каб усталяваць яго, неабходна:
- Перайдзіце ў панэль адміністратара WordPress.
- У раздзеле «Убудовы» выберыце «Дадаць новы».
- Знайдзіце убудова "Yoast SEO" і ўсталюйце яго.
- Актывуйце плагін.
Каб адрэдагаваць файл robots.txt, вам неабходна:
- Перайдзіце ў раздзел «SEO» у бакавым меню панэлі адміністратара і абярыце «Агульныя».
- Перайдзіце на ўкладку «Інструменты».
- Націсніце на «Файлы». Тут вы ўбачыце розныя файлы, у тым ліку robots.txt.
- Увядзіце неабходныя правілы індэксацыі ў адпаведнасці з вашымі патрабаваннямі.
- Пасля ўнясення змяненняў у файл націсніце кнопку «Захаваць змены ў robots.txt».
Звярніце ўвагу, што кожная налада файла robots.txt для WordPress унікальная і залежыць ад канкрэтных патрэбаў і функцый сайта. Універсальнага шаблону, які падыходзіў бы ўсім без выключэння рэсурсам, не існуе. Аднак гэты прыклад і выкарыстанне плагінаў могуць значна спрасціць задачу.
Ручная налада Robots.txt
Гэтак жа вы можаце наладзіць сваю канфігурацыю файла нават пры адсутнасці гатовай CMS для сайта. Таксама карыстальніку неабходна загрузіць файл robots.txt у каранёвай каталог сайта і ўказаць неабходныя правілы. Вось адзін з прыкладаў, у якім пазначаны ўсе даступныя дырэктывы:
User-agent: *
Disallow: /admin/ # Prohibit access to the administrative panel
Disallow: /secret.html # Prohibit access to a specific file
Disallow: /*.pdf$ # Prohibit indexing of certain file types
Disallow: /*?sort= # Prohibit indexing of certain URL parameters
Allow: /public/ # Allow access to public pages
Sitemap: http://yourdomain.com/sitemap.xml # Include the sitemapЯк праверыць файл robots.txt
У якасці дапаможнага інструмента пры праверцы файла robots.txt на наяўнасць памылак рэкамендуецца выкарыстоўваць онлайн-сэрвісы.
Разгледзім на прыкладзе в Яндэкс вэбмайстар абслугоўванне. Для праверкі вам трэба ўставіць спасылку на ваш сайт у адпаведнае поле, калі файл ужо загружаны на сервер. Пасля гэтага інструмент сам загрузіць канфігурацыю файла. Таксама ёсць магчымасць увесці канфігурацыю ўручную:
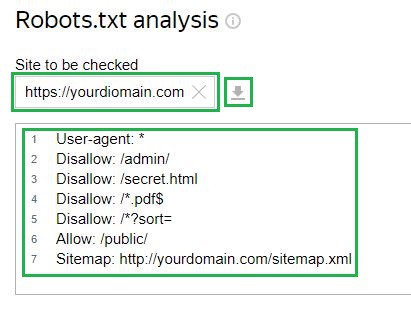
Далей трэба запытаць праверку і дачакацца вынікаў:
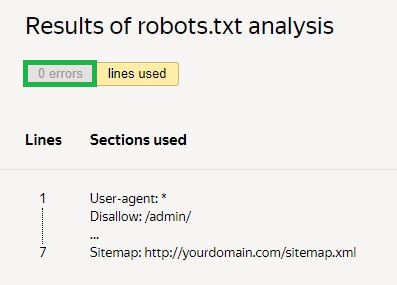
У прыведзеным прыкладзе памылак няма. Пры іх наяўнасці сэрвіс пакажа праблемныя месцы і спосабы іх ліквідацыі.
Conclusion
Падводзячы вынік, мы падкрэслілі, наколькі важны файл robots.txt для кантролю трафіку на сайце. Мы далі парады аб тым, як правільна наладзіць яго для кіравання тым, як пошукавыя сістэмы індэксуюць старонкі. У дадатак да гэтага мы таксама разгледзелі прыклады таго, як правільна выкарыстоўваць гэты файл, і далі інструкцыі, як праверыць, ці ўсе налады працуюць правільна.